44 positive Bewertungen
146 Verwendungen
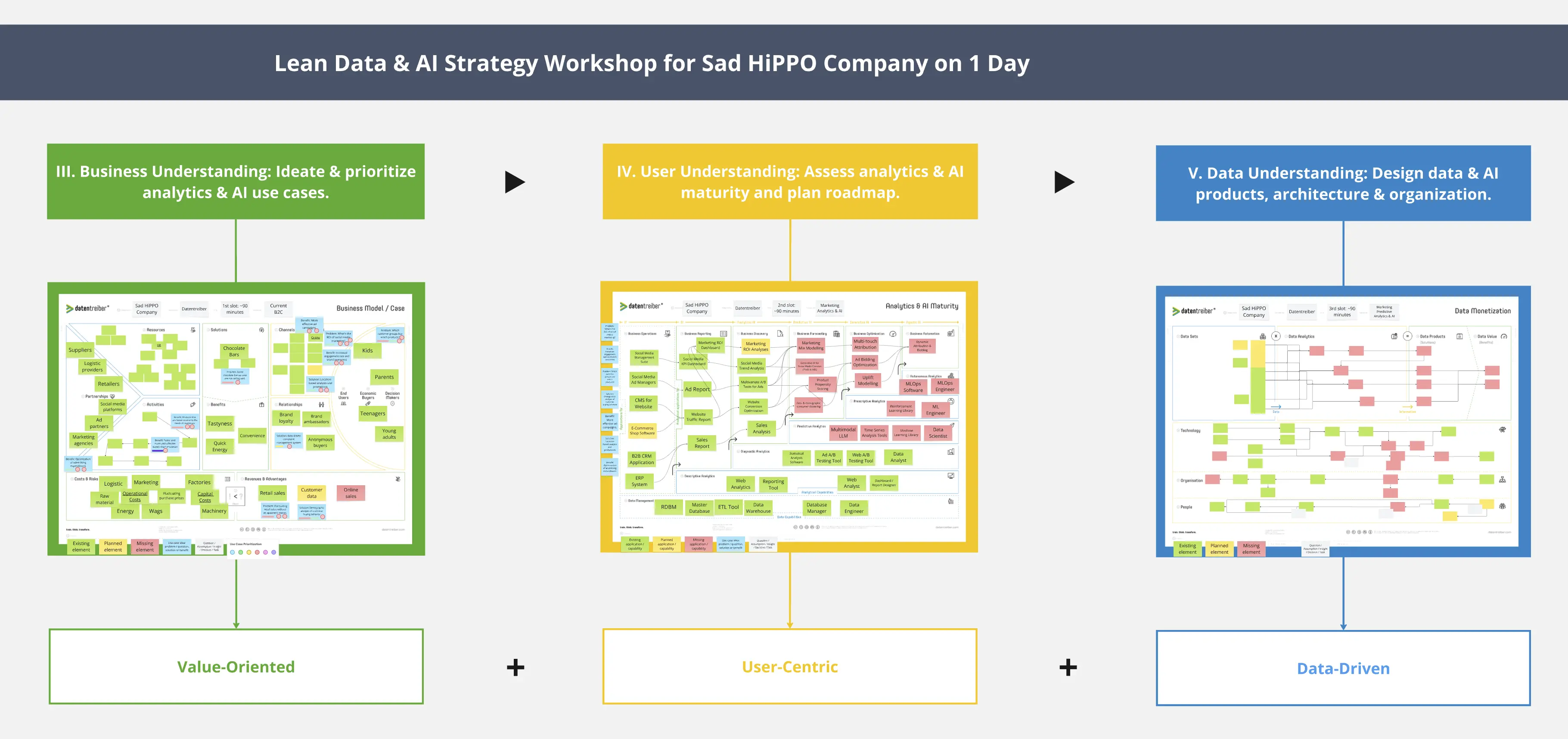
Erkunde die Datenlandschaft, um wesentliche und nützliche Datenquellen für ein Daten-/KI-Produkt zu identifizieren.
Nachdem du mithilfe des Data Monetization-Canvas relevante Datensätze für ein Daten-/KI-Produkt identifiziert hast, bestehen die nächsten Schritte darin, potenzielle Datenquellen zu finden, zu lokalisieren, zu kategorisieren und ihre Verfügbarkeit sowie Qualität zu prüfen – mithilfe des Data Landscape-Canvas.
1. Die Canvas-Kopfzeile ausfüllen:
a) Beschrifte das Label Focus on in der Canvas-Kopfzeile mit einer weißen Notiz, auf der der Name des Daten-/KI-Produkts steht. Du kannst die Focus on-Notiz aus dem Data Monetization-Canvas kopieren, an dem du zuvor gearbeitet hast.
b) Fußzeile: Füge eine Legende mit Notizen in den entsprechenden Farben hinzu:
Grüne Notizen: Daten-Asset: Datenquelle
Gelbe Notizen: Daten-Asset: Datenquelle (mit Problemen)
Rote Notizen: Datenlücke
Blaue Notizen: Daten-/KI-Produkt oder gewünschte Information
Weiße Notizen: Kritische Annahme oder offene Frage
② Um deine Datenerkundung zu steuern, füge eine blaue Notiz mit dem Namen des Data/AI-Produkts oder – für noch engeren Fokus – der gewünschten Information in das mittlere Feld Datenprodukt ein.
③-⑥ Betrachte alle Daten, die für dieses Data/AI-Produkt oder die gewünschte Information notwendig oder nützlich sind. Verwende Notizen in den folgenden Farben oder übernimm vorhandene Notizen aus dem Sort-in-Feld:
Grün: Zeigt an, dass der Datensatz aus einer Datenquelle verfügbar ist. Beschrifte die grüne Notiz wie folgt: "Datensatz: Datenquelle". Wenn der Datensatz in unterschiedlichen Versionen, Formaten, Quellen usw. verfügbar ist, füge mehrere grüne Notizen hinzu und ergänze die Beschriftung um Hinweise, z. B. "Datensatz: Datenquelle (Bemerkung)"
Rot: Zeigt an, dass der Datensatz nicht verfügbar ist. Beschrifte die rote Notiz mit einem aussagekräftigen Titel.
Gelb: Zeigt an, dass der Datensatz verfügbar ist, aber Probleme in Bezug auf Zugänglichkeit, Qualität, Datenschutz, Sicherheit usw. aufweist. Beschrifte die gelbe Notiz wie folgt: "Datensatz: Datenquelle (Problem)".
Platziere diese Notizen in einem der vier Quadranten der Datenlandschaft und besprich anschließend die Auswirkungen:
③ Eigene Daten: Der Einsatz eigener Datensätze kann einen verteidigbaren Wettbewerbsvorteil bieten, da Wettbewerber die Daten möglicherweise nicht reproduzieren können. Eigene Datensätze unterliegen keiner Nutzungsbeschränkung, daher solltest du beim Aufbau deiner Daten-/KI-Produkte eigene Daten priorisieren.
④ Erworbene Daten: Erworbene Daten, z. B. von Kunden oder Lieferanten, können durch individuelle Verträge oder gesetzliche Regelungen (z. B. Datenschutzgesetze) Nutzungsbeschränkungen unterliegen. Wenn mögliche rechtliche Probleme bestehen, ändere die Notiz von grün auf gelb, um dieses Risiko anzuzeigen, und benenne das Problem.
⑤ Kostenpflichtige Daten: Kostenpflichtige Daten unterliegen oft strengeren Beschränkungen, und Exklusivität ist normalerweise nicht garantiert. Es kommt häufig vor, dass verschiedene Abteilungen desselben Unternehmens denselben Datensatz unbeabsichtigt mehrfach kaufen. Um solche Doppelkäufe zu vermeiden, solltest du vor dem Abschluss eines Kaufs immer die Daten und deine bestehenden Lizenzvereinbarungen sorgfältig prüfen.
⑥ Öffentliche Daten: Öffentliche Daten sind in der Regel nicht exklusiv, und viele Datensätze haben einschränkende Nutzungsrechte, z. B. nur für nicht-kommerzielle Nutzung. Besonders zu beachten: Open Data kann unter „Copyleft“-Vereinbarungen stehen – die Nutzung solcher Daten könnte dich dazu verpflichten, auch deine Datenprodukte als Open Source verfügbar zu machen.
Überlege außerdem, ob es sich um Rohdaten oder abgeleitete Daten handelt, und welche Auswirkungen das hat:
a) Rohdaten: Enthalten alle ursprünglichen Informationen, sind aber möglicherweise schwer zu verarbeiten und effizient zu nutzen.
b) Abgeleitete Daten: Diese Daten wurden bearbeitet (z. B. bereinigt, normalisiert, aggregiert, anonymisiert usw.), wodurch ein Teil der ursprünglichen Informationen verloren gehen kann. Berücksichtige, wie sich diese Änderungen auf die Nutzbarkeit der Daten auswirken.
Je nach rechtlichen und verarbeitungsbezogenen Anforderungen lege die am besten geeigneten Datenquellen für dein Daten-/KI‑Produkt fest. Platziere weiße Notizen neben den ausgewählten Datensätzen, um deine Entscheidungen und Gründe zu dokumentieren, und/oder entferne überflüssige Notizen.
Beim maschinellen Lernen verbessert eine größere Datenmenge häufig die Modellleistung. Unternehmen konzentrieren sich jedoch meist nur auf ihre eigenen Daten und übersehen das große Potenzial öffentlicher und kostenpflichtiger Datenquellen. Um deine Datenhorizonte zu erweitern, überlege, zusätzliche Datenquellen zu prüfen:
③ Eigene Daten: Wie kannst du dein Geschäftsmodell und/oder deine Prozesse so anpassen, dass du mehr oder andere Arten von Daten erfassen kannst? Sieh dir die Canvas Business Model, Value Chain, Customer Touchpoints und Analytics & AI Maturity (Box Business Operations) zur Inspiration an.
④ Earned Data: Welche zusätzlichen Daten könnten uns unsere Kunden und Partner liefern? Sieh dir das Business Model-Canvas an, um potenzielle Kunden und Partner zu identifizieren, und nutze (eine Kopie des) Business Model-Canvas, um das Geschäftsmodell deiner (B2B-)Kunden oder -Partner zu analysieren.
⑤ Paid Data: Welche externen Daten könnten wir kaufen oder gegen unsere Daten tauschen? Nutze das Value Chain-Canvas, um die gesamte Wertschöpfungskette deiner Branche zu analysieren, und suche nach den Kunden deiner Kunden und/oder den Lieferanten deiner Lieferanten.
⑥ Public Data: Welche öffentlichen Datenquellen könnten relevante Daten enthalten? Denk über den Tellerrand hinaus und sei kreativ: Gibt es Proxy-Variablen? Zum Beispiel kann die Anzahl der Bearbeitungen auf der Wikipedia-Seite eines Films dessen Einnahmen stark vorhersagen.
Der letzte und entscheidende Schritt ist sicherzustellen, dass alle Datensätze miteinander verknüpft sind. Identifiziere alle notwendigen Identifikatoren oder sonstige Verknüpfungsdaten (z. B. Datum, GPS-Koordinaten, Postleitzahl usw.), lokalisiere die Datenquelle (z. B. Master-Datenbanksystem), prüfe ihre Verfügbarkeit (grüne, gelbe oder rote Notiz) und platziere die Notizen in den entsprechenden Link Data-Feldern (③-⑥c), abhängig von der Herkunft der Datenquelle.
Verbinde mit gestrichelten Linien jede Notiz der Datenquelle mit der entsprechenden Link-Data-Notiz, basierend auf gemeinsamen Identifikatoren oder Verknüpfungsdaten. Am Ende sollte das gesamte Diagramm vollständig verbunden sein, damit eine umfassende Datenintegration und -analyse möglich ist.
Datentreiber bietet dir nicht nur dieses Miroverse-Template, sondern auch:
Das Data & AI Business Design Kit bietet zahlreiche Open-Source-Canvas zur Anwendung der Data & AI Business Design Method.
Außerdem steht die kostenlose Data & AI Business Design Community für Austausch, Veranstaltungen und Experteninhalte zur Verfügung.
Bezahlte online- und Präsenzschulungen mit Zertifikat bietet die Data & AI Business Design Academy an.
Viele weitere Management-Tools, Workshop-Templates und Projektvorlagen sind über unseren kommerziellen Data & AI Business Design Bench erhältlich.
Unser Data & AI Business Consulting unterstützt dich bei deiner Data-&-AI-Strategie sowie bei Innovations- und Transformationsprojekten.
Bei Interesse, Fragen oder Feedback kontaktiere uns unter: info@datentreiber.de.
Copyright: Alle Rechte vorbehalten von Datentreiber GmbH.

Martin Szugat
Data & AI Business Catalyst @ Datentreiber
To help companies to transform into data-driven, AI-powered businesses and innovate data & AI products, I've invented the Data & AI Business Design Method and our company Datentreiber open sourced the Data & AI Business Design Kit. I'm a Miro MVP and a Miro Solution Partner.