5 likes
7 utilisations
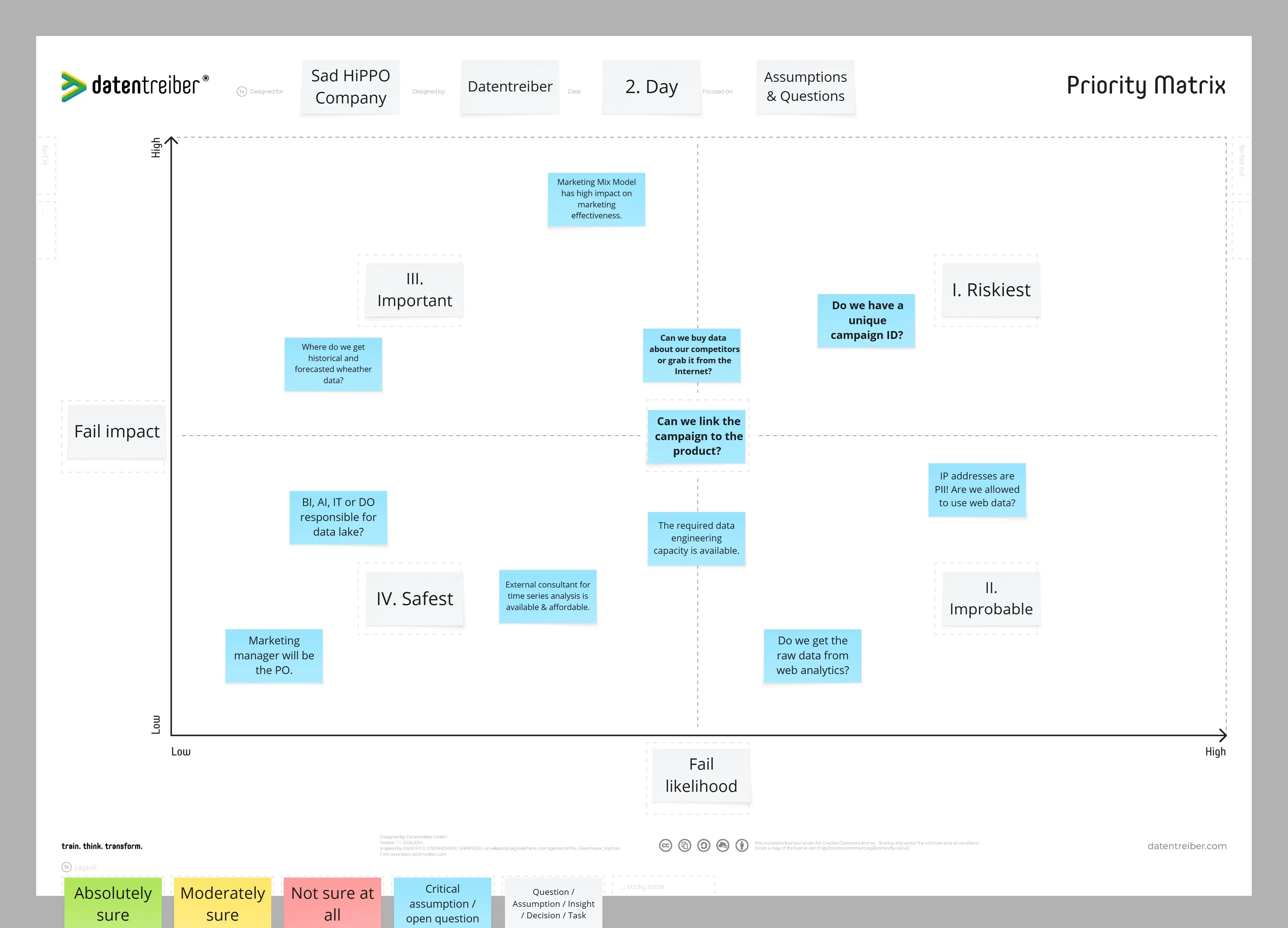
Choisissez la meilleure application ou le meilleur cas d’utilisation de données et d’IA selon le rapport coût-valeur.
Si plusieurs idées de cas d’utilisation pour des applications analytiques et d’IA existent dans le même domaine d’application et au même niveau de maturité analytique et IA, et qu’il est difficile de déterminer quelles priorités explorer lors de l’atelier ou à implémenter par la suite, utilisez la méthode PICK. Cette méthode aide à prendre rapidement des décisions de groupe basées sur une « guesstimation » – une estimation approximative de la complexité par rapport à la valeur de chaque application. L’acronyme "PICK" représente les quatre quadrants de la matrice de priorisation : "Possible", "Implement", "Challenge" et "Kill".
① Remplissez l’en-tête du canevas :
a) Étiquetez Focus sur dans l’en-tête du canevas avec un pense-bête blanc pour le domaine d’application et la maturité analytique et IA.
② Étiquetez les axes et les quadrants avec des pense-bêtes blancs :
a) Abscisse : « Complexité technique, analytique et organisationnelle » - la complexité peut provenir de diverses sources, telles qu’un paysage de données fragmenté, des obstacles techniques ou des processus complexes. Cette complexité augmente non seulement les coûts de mise en œuvre et d’exploitation, mais entraîne également des retards qui reportent la réalisation de la valeur. De plus, elle accroît les risques économiques, écologiques, juridiques et techniques.
b) Ordonnée : « Valeur ajoutée à l’objectif » - Évaluez la valeur d’une application en fonction de sa contribution à l’atteinte de l’objectif fixé lors de l’atelier.
③ Étiquetez les quadrants : Chacun des quatre quadrants doit être étiqueté selon l’acronyme "PICK". L’ordre est montré ci-dessous.
a) I. Quadrant : « I. Mettre en œuvre »— vous devriez mettre en œuvre ces applications de faible complexité et de grande valeur.
b) II. Quadrant : "III. Challenge" - Vous devez challenger ces applications à forte complexité et grande valeur avant de les implémenter.
c) III. Quadrant : "II. Possible" - Vous pourriez implémenter ces applications à faible complexité et faible valeur, s’il n’y a pas d’autres applications à faible complexité et grande valeur.
d) IV. Quadrant : "IV. Kill" - Vous devriez "éliminer" ces applications qui sont très complexes mais peu précieuses. Placez-les dans votre backlog (par exemple, catalogue de cas d’utilisation) jusqu’à ce que les structures techniques, organisationnelles et de personnel nécessaires soient développées pour réduire leur complexité.
④ Élément d’ancrage : Sélectionnez une application dans le champ "Classer dans" sur le bord gauche qui a une complexité et une valeur moyennes. Placez-la au centre du canevas. Elle servira d’élément d’ancrage, fournissant un point de référence pour comparer toutes les autres applications en les classant selon leur complexité et leur valeur.
Astuce : Si vous avez déjà implémenté une application dans le même domaine et niveau de maturité analytique & IA ayant une complexité et une valeur moyennes, utilisez cette application existante comme votre élément d’ancrage.
Maintenant, commencez à travailler avec les quadrants que vous avez étiquetés à l’étape ③ : Faites évaluer chaque application restante par les participants par rapport à celles déjà positionnées sur la matrice, en particulier par rapport à l’élément d’ancrage. Ajustez le placement en fonction de cette comparaison :
Complexité : Déplacez l’application vers la droite si sa complexité est supérieure à celle de l’ancre, et vers la gauche si elle est inférieure.
Valeur : Placez l’application plus haut si sa valeur est supérieure à celle de l’ancre, et plus bas si elle est inférieure.
De plus, utilisez des pense-bêtes blancs pour noter toutes les hypothèses formulées lors de vos estimations, afin de garantir la clarté et la transparence du processus de prise de décision.
Conseil : Si une application dépend d’une autre, illustrez cette dépendance en les connectant par des flèches. Placez l’application dépendante plus à droite et plus haut, ce qui indique une complexité accrue en raison de la dépendance à une autre application et une valeur supérieure car elle apporte des avantages supplémentaires.
Optionnel : S’il y a beaucoup de débats ou d’incertitudes sur la probabilité d’échec ou l’impact, utilisez des couleurs sur les pense-bêtes pour indiquer votre degré de certitude :
Vert : Absolument sûr
Jaune : Moyennement sûr
Rouge : Pas du tout sûr
Recherchez des applications dans le I. Quadrant « Implémenter » : ce sont votre ensemble pertinent.
Si ce quadrant est vide, concentrez-vous plutôt sur le III. Quadrant "Possible". Si les deux quadrants sont dépourvus d’entrées, réévaluez votre élément d’ancrage — il ne représente peut-être pas avec précision le scénario moyen. Dans ce cas, refaites l’étape II. Guesstimation en utilisant une application "moyenne" plus représentative.
Important : L’élément d’ancrage fait également partie de votre ensemble pertinent !
Parmi l’ensemble pertinent, sélectionnez une application qui ne dépend d’aucune application antérieure ou de prérequis comme la prochaine meilleure application. Discutez de ses avantages et inconvénients. Si un consensus sur la prochaine meilleure application n’est pas atteint, procédez à un vote ou laissez le décideur finaliser la décision.
Datentreiber vous offre non seulement ce modèle Miroverse, mais aussi :
Le Data & AI Business Design Kit propose de nombreux canevas open source pour appliquer la méthode de conception Data & IA Business.
De plus, la communauté Data & AI Business Design est gratuite et disponible pour l’échange, les événements, et le contenu expert.
Des formations en ligne et sur site payantes avec certification sont disponibles à la Data & AI Business Design Academy.
De nombreux outils de gestion additionnels, modèles d’atelier et plans de projet sont disponibles via notre Data & AI Business Design Bench commercial.
Notre service de conseil en stratégie data & IA propose un accompagnement pour vos projets en stratégie, innovation et transformation concernant les données et l’IA.
Si vous êtes intéressé(e) ou si vous avez des questions ou des feedbacks, veuillez nous contacter à : info@datentreiber.de.
Droits d’auteur : Tous les droits sont réservés par Datentreiber GmbH.

Martin Szugat
Data & AI Business Catalyst @ Datentreiber
To help companies to transform into data-driven, AI-powered businesses and innovate data & AI products, I've invented the Data & AI Business Design Method and our company Datentreiber open sourced the Data & AI Business Design Kit. I'm a Miro MVP and a Miro Solution Partner.

