44 likes
146 utilisations
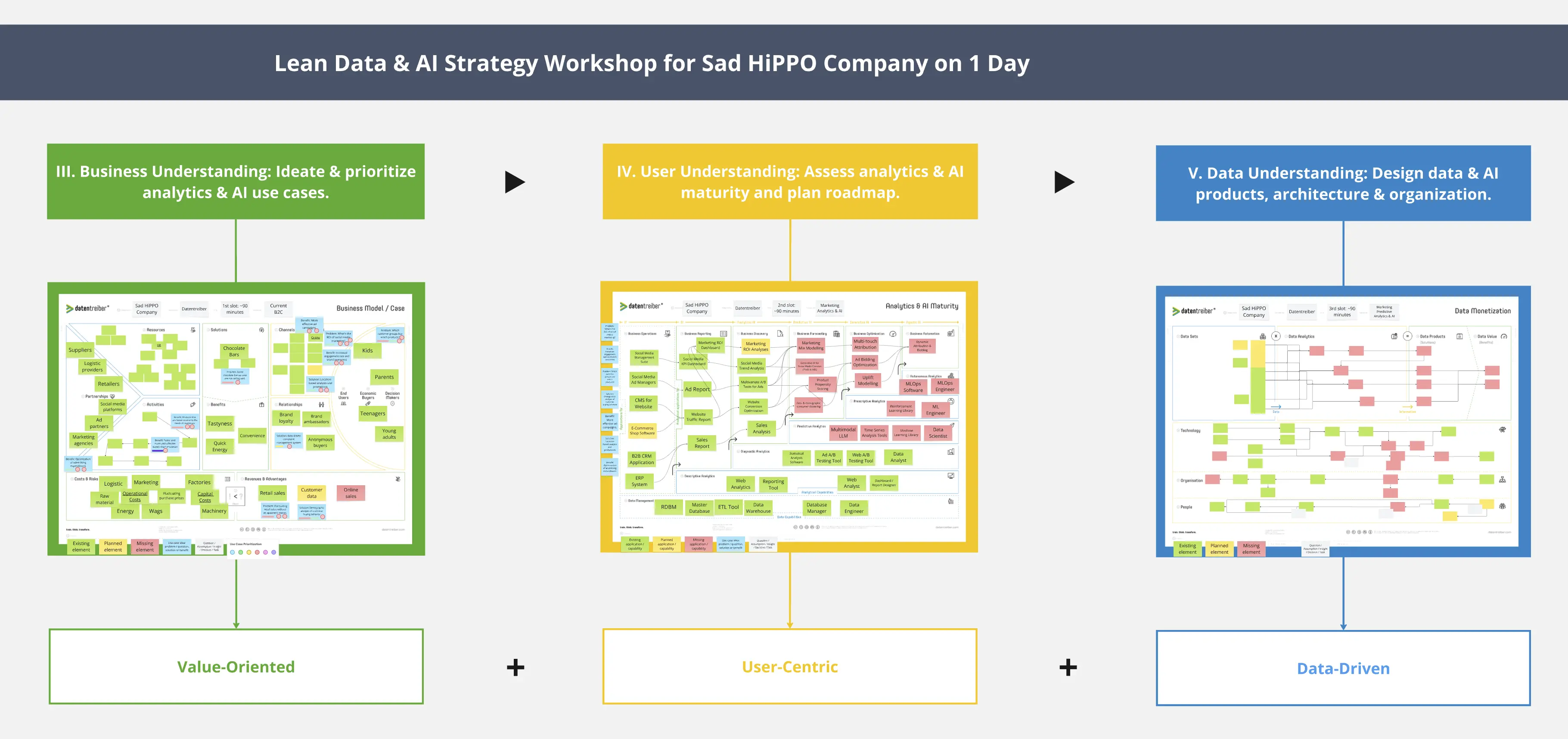
Explorez le paysage des données pour repérer les sources de données essentielles et utiles à un produit data/IA.
Après avoir identifié des jeux de données pertinents pour un produit data/IA à l’aide du canevas Data Monetization, vos prochaines étapes consistent à identifier, localiser, catégoriser et vérifier la disponibilité et la qualité des sources de données potentielles en utilisant le canevas Data Landscape.
1. Remplissez l’en-tête du canevas :
a) Ajoutez le badge Focus sur dans l’en-tête du canevas à l’aide d’un pense-bête blanc portant le nom du produit de données/IA. Vous pouvez copier le pense-bête Focus sur depuis le Data Monetization canevas sur lequel vous travailliez précédemment.
b) Pied de page : Ajoutez une légende avec des pense-bêtes de la couleur correspondante :
Pense-bêtes verts : Ressource de données : source de données
Pense-bêtes jaunes : Ressource de données : source de données (avec un problème)
Pense-bêtes rouges : lacune de données
Pense-bêtes bleus : produit de données/IA ou information souhaitée
Pense-bêtes blancs : hypothèse critique ou question ouverte
② Pour orienter votre exploration des données, ajoutez un pense-bête bleu portant le nom du produit data/IA ou, pour un focus encore plus restreint, l’information souhaitée dans la zone centrale Data Product.
③-⑥ Prenez en compte toutes les données nécessaires ou utiles pour ce produit data/IA ou pour l’information souhaitée. Utilisez des pense-bêtes des couleurs suivantes, ou incorporez ceux déjà présents dans la zone Sort in :
Vert : Indique que le jeu de données est disponible auprès d’une source de données. Étiquetez le pense-bête vert comme suit : " jeu de données : source de données". Si le jeu de données est disponible en différentes versions, formats, sources, etc., ajoutez plusieurs pense-bêtes verts et précisez une remarque dans le libellé, p. ex. " jeu de données : source de données (remarque)"
Rouge : Indique que le jeu de données n’est pas disponible. Donnez au pense-bête rouge un titre descriptif.
Jaune : Indique que le jeu de données est disponible mais présente des problèmes liés à l’accessibilité, à la qualité, à la confidentialité, à la sécurité, etc. Étiquetez le pense-bête jaune comme suit : " jeu de données : source de données (problème)"
Placez ces pense-bêtes dans l’un des quatre quadrants du paysage de données, puis discutez des implications :
③ Données propriétaires : L’utilisation de jeux de données propriétaires peut offrir un avantage concurrentiel défendable, car les concurrents peuvent ne pas être en mesure de reproduire ces données. Les jeux de données propriétaires n’ont pas de limitation d’utilisation, donc priorisez la création de vos produits data/IA sur des données propriétaires.
④ Données acquises : Les données acquises, par exemple celles provenant de clients ou de fournisseurs, peuvent être soumises à des restrictions d’utilisation imposées par des contrats individuels ou par des réglementations légales (p. ex., les lois sur la protection des données). Si des problèmes juridiques potentiels existent, changez le pense-bête de vert à jaune pour indiquer ce risque et précisez le problème.
⑤ Données payantes : Les données payantes s’accompagnent souvent de restrictions plus strictes, et l’exclusivité n’est généralement pas garantie. Il est fréquent que différents services au sein d’une même entreprise achètent sans le savoir plusieurs fois le même jeu de données. Pour éviter de telles redondances, effectuez systématiquement une revue approfondie des données et de vos contrats de licence avant de finaliser tout achat.
⑥ Données publiques : Les données publiques manquent généralement d’exclusivité et de nombreux jeux de données sont assortis de droits d’utilisation restrictifs, par exemple réservés à un usage non commercial. Notamment, les données ouvertes peuvent être soumises à des licences « copyleft », ce qui pourrait vous obliger à rendre vos produits de données open source.
Décidez également s’il s’agit de données brutes ou dérivées et réfléchissez aux implications :
a) Données brutes : Contient toutes les informations d’origine, mais peut être difficile à traiter et à exploiter efficacement.
b) Données dérivées : Ces données ont subi des traitements tels que le nettoyage, la normalisation, l’agrégation, l’anonymisation, etc., entraînant la perte d’une partie des informations d’origine. Réfléchissez aux conséquences de ces transformations sur l’utilité des données.
En fonction des exigences légales et de traitement, déterminez les sources de données les plus adaptées à votre produit de données/IA. Placez des pense-bêtes blancs à côté des jeux de données sélectionnés pour consigner vos décisions et vos motifs, et/ou retirez les pense-bêtes superflus.
En apprentissage automatique, la quantité améliore souvent les performances du modèle. Cependant, les entreprises se concentrent généralement uniquement sur leurs propres données, en négligeant le vaste potentiel des sources publiques et payantes. Pour élargir vos horizons de données, envisagez d’explorer des sources de données supplémentaires :
③ Données détenues : Comment pouvons-nous modifier notre modèle économique et/ou nos processus pour collecter davantage ou différents types de données ? Consultez les canevas Modèle économique, Chaîne de valeur, Points de contact client et Maturité Analytics & IA (boîte Opérations métier) pour en tirer des perspectives.
④ Données acquises : Quelles données supplémentaires nos clients et partenaires pourraient-ils nous fournir ? Consultez le canevas Business Model pour identifier les clients et partenaires potentiels et utilisez (une copie du) canevas Business Model pour analyser le modèle commercial de vos clients ou partenaires (B2B).
⑤ Données achetées : Quelles données externes pourrions-nous acheter ou obtenir en échange de nos données ? Utilisez le canevas Value Chain pour analyser l’ensemble de la chaîne de valeur de votre secteur et repérer les clients de vos clients et/ou les fournisseurs de vos fournisseurs.
⑥ Données publiques : Quelles sources de données publiques pourraient contenir des informations pertinentes ? Sortez des sentiers battus et faites preuve de créativité : existe-t-il des variables de substitution ? Par exemple, le nombre de modifications d’une page Wikipédia sur un film peut fortement prédire les recettes de ce film.
La dernière et essentielle étape consiste à s’assurer que tous les jeux de données sont liés entre eux. Par exemple, identifiez tous les identifiants nécessaires ou autres données de liaison (par ex. date, coordonnées GPS, code postal, etc.), localisez la source de données (par ex. système principal de base de données), évaluez sa disponibilité (pense-bête vert, jaune ou rouge) et placez les pense-bêtes dans les cases Liens de données correspondantes (③-⑥c), selon l’origine des sources de données.
Reliez ensuite, à l’aide de lignes pointillées, chaque pense-bête représentant une source de données au pense-bête correspondant de liens de données en vous basant sur les identifiants ou données de liaison partagés. À la fin, l’ensemble du graphe doit être entièrement connecté pour permettre une intégration et une analyse complètes des données.
Datentreiber vous propose non seulement ce modèle Miroverse, mais aussi :
Le Data & AI Business Design Kit propose de nombreux canevas open source pour appliquer la méthode Data & AI Business Design.
De plus, la Data & AI Business Design Community gratuite est disponible pour les échanges, les événements et le contenu d’experts.
Des formations payantes en ligne et sur site, avec certification, sont disponibles à la Data & AI Business Design Academy.
De nombreux outils de gestion supplémentaires, modèles d’atelier et plans de projet sont disponibles dans notre Data & AI Business Design Bench commercial.
Notre Data & AI Business Consulting propose un service d’assistance pour votre stratégie data et IA, ainsi que pour vos projets d’innovation et de transformation.
Si vous êtes intéressé ou si vous avez des questions ou du feedback, contactez-nous à : info@datentreiber.de.
Droits d’auteur : Tous droits réservés par Datentreiber GmbH.

Martin Szugat
Data & AI Business Catalyst @ Datentreiber
To help companies to transform into data-driven, AI-powered businesses and innovate data & AI products, I've invented the Data & AI Business Design Method and our company Datentreiber open sourced the Data & AI Business Design Kit. I'm a Miro MVP and a Miro Solution Partner.