44 Me gusta
146 usos
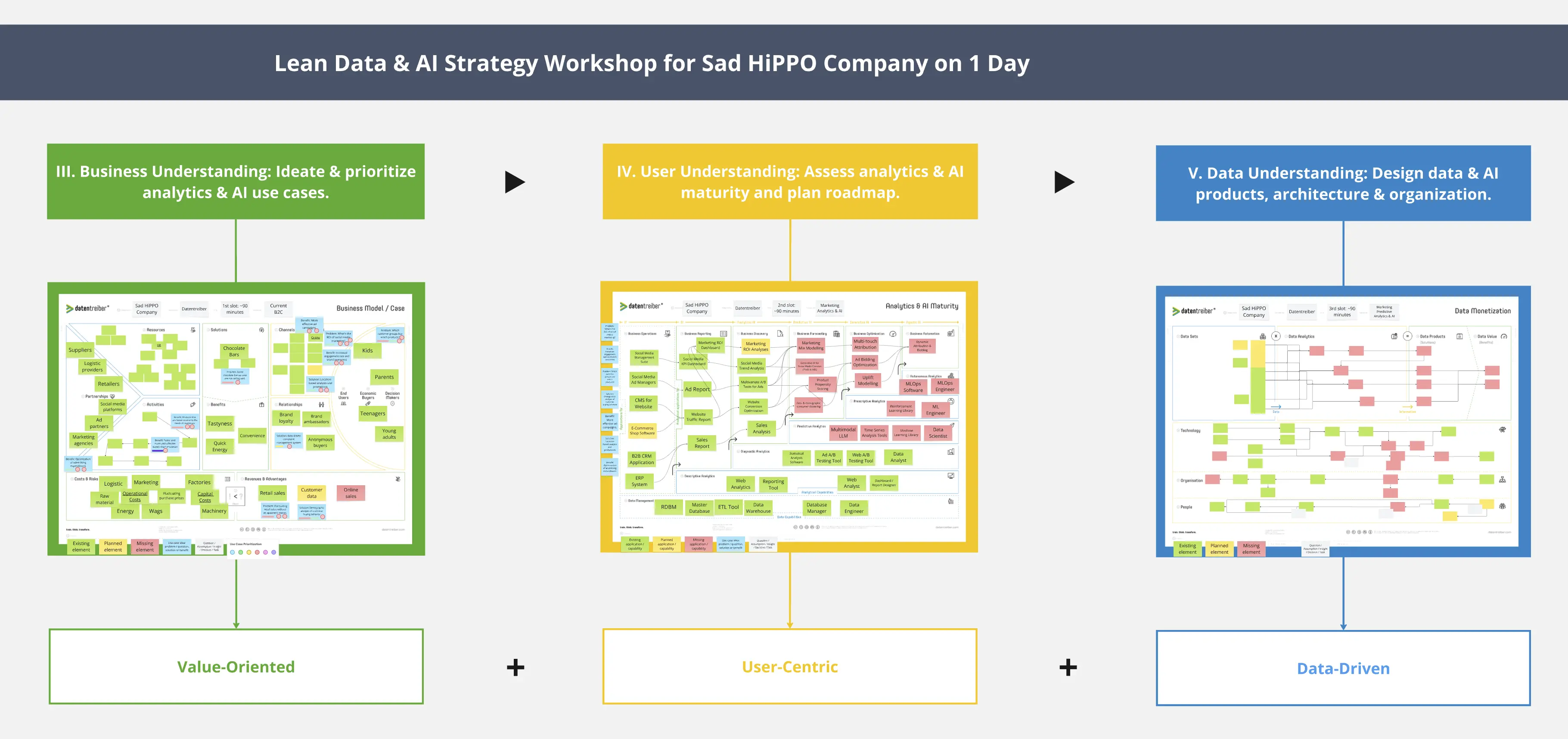
Explora el panorama de datos para identificar fuentes de datos esenciales y útiles para un producto de datos/IA.
Habiendo identificado los conjuntos de datos relevantes para un producto de datos/IA usando el Data Monetization lienzo, tus siguientes pasos consisten en identificar, localizar, categorizar y verificar la disponibilidad y calidad de las posibles fuentes de datos usando el Data Landscape lienzo.
1. Rellena el encabezado del lienzo:
a) Etiqueta Focus on en el encabezado del lienzo con una nota adhesiva blanca con el nombre del producto de datos/IA. Puedes copiar la nota adhesiva Focus on del Data Monetization lienzo en el que trabajabas anteriormente.
b) Pie de página: Agrega una leyenda con notas adhesivas del color correspondiente:
Notas adhesivas verdes: Activo de datos: fuente de datos
Notas adhesivas amarillas: Activo de datos: fuente de datos (con incidencia)
Notas adhesivas rojas: Brecha de datos
Notas adhesivas azules: Producto de datos/IA o información deseada
Notas adhesivas blancas: Suposición crítica o pregunta abierta
② Para orientar tu exploración de datos, añade una nota adhesiva azul con el nombre del producto de datos/IA o —para un enfoque aún más preciso— la información deseada en el recuadro central Data Product.
③-⑥ Considera todos los datos necesarios o útiles para este producto de datos/IA o para la información deseada. Usa notas adhesivas de los siguientes colores, o incorpora las que ya existan en el recuadro Sort in:
Verde: Indica que el conjunto de datos está disponible en una fuente de datos. Etiqueta la nota adhesiva verde de la siguiente manera: " conjunto de datos: fuente de datos". Si el conjunto de datos está disponible en diferentes versiones, formatos, fuentes, etc., añade varias notas adhesivas verdes y agrega observaciones en la etiqueta, p. ej., "conjunto de datos: fuente de datos (observación)"
Rojo: Indica que el conjunto de datos no está disponible. Etiqueta la nota adhesiva roja con un título descriptivo.
Amarillo: Indica que el conjunto de datos está disponible pero presenta incidencias relacionadas con accesibilidad, calidad, privacidad, seguridad, etc. Etiqueta la nota adhesiva amarilla de la siguiente manera: "conjunto de datos: fuente de datos (incidencia)".
Coloca estas notas adhesivas en uno de los cuatro cuadrantes del panorama de datos, luego discute las implicaciones:
③ Datos propios: El uso de conjuntos de datos propios puede proporcionar una ventaja competitiva defendible, ya que los competidores tal vez no puedan replicar esos datos. Los conjuntos de datos propios no tienen limitaciones de uso, por lo que prioriza basar tus productos de datos/IA en datos propios.
④ Datos ganados: Los datos ganados, como los procedentes de clientes o proveedores, pueden tener restricciones de uso impuestas por contratos individuales o normativas legales (por ejemplo, leyes de privacidad de datos). Si existen posibles problemas legales, cambia la nota adhesiva de verde a amarillo para indicar este riesgo y nombra la incidencia.
⑤ Datos de pago: Los datos de pago suelen venir con limitaciones más estrictas, y la exclusividad generalmente no está garantizada. Es común que diferentes departamentos dentro de la misma empresa compren sin saberlo el mismo conjunto de datos varias veces. Para evitar esa redundancia, siempre realiza una revisión exhaustiva de los datos y de los acuerdos de licencia de datos existentes antes de finalizar cualquier compra.
⑥ Datos públicos: Los datos públicos normalmente carecen de exclusividad, y muchos conjuntos de datos incluyen derechos de uso restrictivos, como uso únicamente no comercial. En particular, los datos abiertos pueden estar sujetos a acuerdos de "copyleft": usar esos datos podría requerir que tus productos de datos también sean de código abierto.
También decide si se trata de datos sin procesar o datos derivados y piensa en las implicaciones:
a) Datos sin procesar: Contienen toda la información original, pero pueden ser difíciles de manejar y usar de forma eficiente.
b) Datos derivados: Estos datos han pasado por procesos como limpieza, normalización, agregación, anonimización, etc., lo que conlleva la pérdida de parte de la información original. Considera las implicaciones de estos cambios sobre la utilidad de tus datos.
Según los requisitos legales y de procesamiento, determina las fuentes de datos más adecuadas para tu producto de datos/IA. Coloca notas adhesivas blancas junto a los conjuntos de datos seleccionados para documentar tus decisiones y las razones, y/o elimina las notas adhesivas innecesarias.
En el aprendizaje automático, la cantidad suele mejorar el rendimiento del modelo. Sin embargo, las empresas normalmente se concentran solo en sus propios datos, pasando por alto el enorme potencial de las fuentes de datos públicas y de pago. Para ampliar tus horizontes de datos, considera explorar fuentes de datos adicionales:
③ Datos propios: ¿Cómo podemos modificar nuestro modelo de negocio y/o procesos para captar más o distintos tipos de datos? Revisa los lienzos Business Model, Value Chain, Customer Touchpoints y Analytics & AI Maturity (el recuadro Business Operations) para obtener insights.
④ Earned Data: ¿Qué datos adicionales podrían proporcionarnos nuestros clientes y socios? Revisa el Business Model lienzo para identificar clientes y socios potenciales y usa (una copia del) Business Model lienzo para analizar el modelo de negocio de tus clientes o socios (B2B).
⑤ Paid Data: ¿Qué datos externos podríamos comprar o intercambiar por nuestros datos? Usa el Value Chain lienzo para analizar toda la cadena de valor de tu industria y busca a los clientes de tus clientes y/o a los proveedores de tus proveedores.
⑥ Public Data: ¿Qué fuentes de datos públicas podrían contener datos relevantes? Piensa de forma creativa y fuera de lo común: ¿existen variables proxy? Por ejemplo, el número de ediciones en una página de Wikipedia sobre una película puede predecir con bastante precisión los ingresos de la película.
El paso final y crítico es asegurarte de que todos los conjuntos de datos estén enlazados. Por ejemplo, identifica todos los identificadores necesarios u otros datos de vinculación (p. ej., fecha, coordenadas GPS, código postal, etc.), localiza la fuente de datos (p. ej., sistema maestro de base de datos), evalúa su disponibilidad (nota adhesiva verde, amarilla o roja) y coloca las notas adhesivas en los recuadros correspondientes de Vinculación de datos (③-⑥c), según el origen de las fuentes de datos.
Usando líneas punteadas, conecta cada nota adhesiva de fuente de datos con la nota adhesiva correspondiente de datos de vinculación según los identificadores compartidos u otros datos de vinculación. Al final, todo el diagrama debe estar completamente conectado para permitir una integración y un análisis de datos exhaustivos.
Datentreiber no solo te ofrece esta plantilla de Miroverse, sino también:
El Data & AI Business Design Kit ofrece numerosos lienzos de código abierto para aplicar el método Data & AI Business Design.
Además, la Data & AI Business Design Community gratuita está disponible para intercambio, eventos y contenido de expertos.
Cursos de formación online y presenciales de pago con certificación están disponibles en la Data & AI Business Design Academy.
Muchas herramientas de gestión adicionales, plantillas para talleres y modelos de proyecto están disponibles en nuestro comercial Data & AI Business Design Bench.
Nuestro Data & AI Business Consulting ofrece soporte para tu estrategia de Data & AI, innovación y proyectos de transformación.
Si estás interesado o tienes alguna pregunta o comentario, contáctanos en: info@datentreiber.de.
Derechos de autor: Todos los derechos reservados por Datentreiber GmbH.

Martin Szugat
Data & AI Business Catalyst @ Datentreiber
To help companies to transform into data-driven, AI-powered businesses and innovate data & AI products, I've invented the Data & AI Business Design Method and our company Datentreiber open sourced the Data & AI Business Design Kit. I'm a Miro MVP and a Miro Solution Partner.