44 curtidas
146 usos
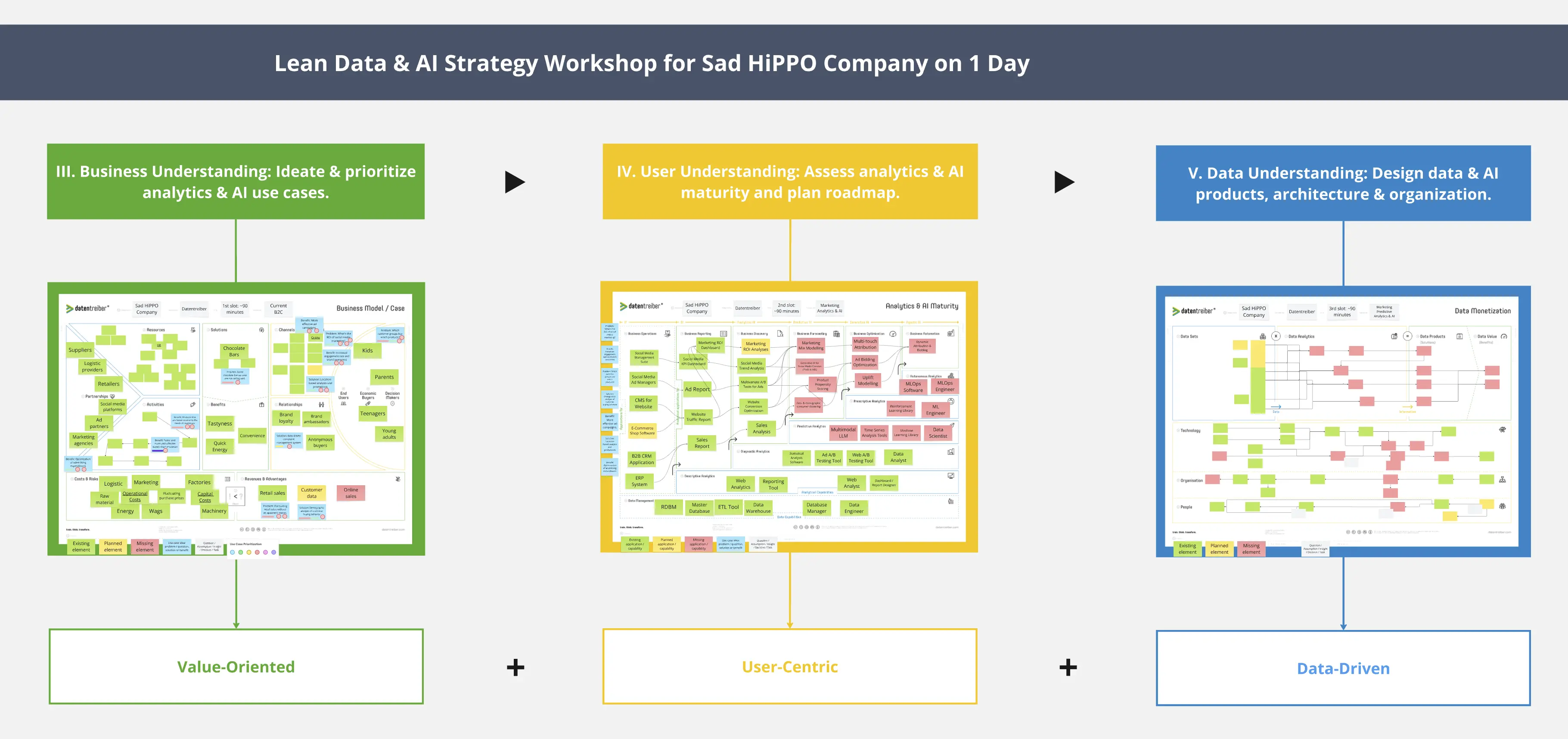
Explore o panorama de dados para identificar fontes de dados essenciais e úteis para um produto de dados/IA.
Depois de identificar conjuntos de dados relevantes para um produto de dados/IA usando o Data Monetization canvas, os próximos passos são identificar, localizar, categorizar e verificar a disponibilidade e a qualidade de potenciais fontes de dados usando o Data Landscape canvas.
1. Preencha o cabeçalho do canvas:
a) Coloque a etiqueta Foco em no cabeçalho do canvas em uma nota adesiva branca com o nome do produto de dados/IA. Você pode copiar a nota adesiva Foco em do Data Monetization canvas em que estava trabalhando.
b) Rodapé: adicione uma legenda com notas adesivas nas cores correspondentes:
Notas adesivas verdes: Ativo de dados: fonte de dados
Notas adesivas amarelas: Ativo de dados: fonte de dados (com problema)
Notas adesivas vermelhas: Lacuna de dados
Notas adesivas azuis: Produto de dados/IA ou informação desejada
Notas adesivas brancas: Pressuposto crítico ou questão em aberto
② Para orientar sua exploração de dados, adicione uma nota adesiva azul com o nome do produto de dados/IA ou, para um foco ainda maior, a informação desejada na caixa central Data Product.
③-⑥ Considere todos os dados necessários ou úteis para este produto de dados/IA ou para a informação desejada. Use notas adesivas nas seguintes cores, ou incorpore as já existentes na caixa Sort in:
Verde: indica que o conjunto de dados está disponível em uma fonte de dados. A etiqueta da nota adesiva verde deve ser: "conjunto de dados: fonte de dados". Se o conjunto de dados estiver disponível em versões, formatos ou fontes diferentes, adicione várias notas adesivas verdes e acrescente observações na etiqueta, por exemplo: "conjunto de dados: fonte de dados (observação)"
Vermelho: indica que o conjunto de dados não está disponível. Etiquete a nota adesiva vermelha com um título descritivo.
Amarelo: indica que o conjunto de dados está disponível, mas apresenta problemas relacionados à acessibilidade, qualidade, privacidade, segurança etc. A etiqueta da nota adesiva amarela deve ser: "conjunto de dados: fonte de dados (problema)".
Coloque essas notas adesivas em um dos quatro quadrantes do data landscape e depois discutam as implicações:
③ Dados próprios: Usar conjuntos de dados próprios pode oferecer uma vantagem competitiva defensável, já que concorrentes podem não conseguir replicar os dados. Conjuntos de dados próprios não têm limitação de uso, portanto priorize basear seus produtos de dados e IA em dados próprios.
④ Dados obtidos: Dados obtidos, como os de clientes ou fornecedores, podem ter restrições de uso impostas por contratos individuais ou por normas legais (por exemplo, leis de privacidade de dados). Se houver possíveis problemas legais, troque a nota adesiva de verde para amarela para indicar esse risco e descreva o problema.
⑤ Dados pagos: Dados pagos frequentemente vêm com restrições mais rígidas, e exclusividade geralmente não é garantida. É comum que diferentes departamentos dentro da mesma empresa comprem o mesmo conjunto de dados várias vezes sem perceber. Para evitar essa redundância, sempre faça uma revisão completa dos dados e dos seus acordos de licenças antes de finalizar qualquer compra.
⑥ Dados públicos: Dados públicos normalmente não são exclusivos e muitos conjuntos de dados têm restrições de uso, como uso apenas para fins não comerciais. Vale notar que dados abertos podem estar sujeitos a acordos de "copyleft": usar esses dados pode exigir que seus produtos de dados também sejam de código aberto.
Decida também se são dados brutos ou derivados e reflita sobre as implicações:
a) Dados brutos: Contêm todas as informações originais, mas podem ser difíceis de manusear e usar com eficiência.
b) Dados derivados: Esses dados passaram por processos como limpeza, normalização, agregação, anonimização etc., o que resulta na perda de parte das informações originais. Considere as implicações dessas mudanças na utilidade dos dados.
Dependendo dos requisitos legais e de processamento, determine as fontes de dados mais adequadas para seu produto de dados/IA. Coloque notas adesivas brancas ao lado dos conjuntos de dados selecionados para documentar suas decisões e motivos e/ou remova as notas adesivas desnecessárias.
No aprendizado de máquina, mais dados costumam melhorar o desempenho do modelo. No entanto, as empresas costumam se concentrar apenas nos próprios dados, deixando de lado o grande potencial das fontes de dados públicas e pagas. Para ampliar seus horizontes de dados, considere explorar fontes de dados adicionais:
③ Owned Data: Como podemos modificar nosso modelo de negócio e/ou processos para capturar mais ou diferentes tipos de dados? Revise os canvases Business Model, Value Chain, Customer Touchpoints e Analytics & AI Maturity (caixa Business Operations) em busca de insights.
④ Earned Data: Que dados adicionais nossos clientes e parceiros poderiam nos fornecer? Verifique o Business Model canvas para identificar clientes e parceiros potenciais e use (uma cópia do) Business Model canvas para analisar o modelo de negócios dos seus clientes ou parceiros (B2B).
⑤ Paid Data: Que dados externos poderíamos comprar ou trocar pelos nossos dados? Use o Value Chain canvas para analisar toda a cadeia de valor do seu setor e procurar os clientes dos seus clientes e/ou os fornecedores dos seus fornecedores.
⑥ Public Data: Quais fontes públicas podem conter dados relevantes? Pense fora da caixa e seja criativo: existem variáveis proxy? Por exemplo, o número de edições na página da Wikipedia sobre um filme pode prever fortemente a receita do filme.
A etapa final e crítica é garantir que todos os conjuntos de dados se conectem. Por exemplo, identifique todos os identificadores necessários ou outros dados de vinculação (por exemplo, data, coordenadas GPS, CEP etc.), localize a fonte de dados (por exemplo, sistema mestre de banco de dados), avalie sua disponibilidade (notas adesivas verdes, amarelas ou vermelhas) e coloque notas adesivas nas caixas correspondentes Dados de vinculação (③-⑥c), dependendo da origem das fontes de dados.
Usando linhas pontilhadas, conecte cada nota adesiva da fonte de dados à nota adesiva correspondente de dados de vinculação com base em identificadores compartilhados ou dados de vinculação. Ao final, todo o grafo deve estar completamente conectado para permitir uma integração e análise abrangentes dos dados.
A Datentreiber oferece não apenas este modelo do Miroverse, mas também:
O Kit Data & AI Business Design oferece diversos canvases de código aberto para aplicar o método Data & AI Business Design.
Além disso, a comunidade Data & AI Business Design gratuita está disponível para troca, eventos e conteúdo de especialistas.
Cursos de treinamento pagos, online e presenciais, com certificação estão disponíveis na Academia Data & AI Business Design.
Muitas ferramentas de gestão adicionais, modelos de workshop e planos de projeto estão disponíveis no nosso Data & AI Business Design Bench comercial.
Nossa Data & AI Business Consulting oferece suporte à sua estratégia de dados e IA, inovação e projetos de transformação.
Se tiver interesse, dúvidas ou feedback, entre em contato: info@datentreiber.de.
Direitos autorais: Todos os direitos reservados por Datentreiber GmbH.

Martin Szugat
Data & AI Business Catalyst @ Datentreiber
To help companies to transform into data-driven, AI-powered businesses and innovate data & AI products, I've invented the Data & AI Business Design Method and our company Datentreiber open sourced the Data & AI Business Design Kit. I'm a Miro MVP and a Miro Solution Partner.