ER図の描き方:完全なステップバイステップガイド
概要
このガイドでは、次のことを学びます:
- エンティティ・リレーションシップ図とは何か、そして実装前にコストのかかるデータベース設計ミスを防ぐために、なぜそれらが不可欠なのか
- ERDの活用シーン:新規プロジェクトの立ち上げから、チームメンバーの受け入れ、主要な機能追加の計画まで
- ERDの主要な構成要素:エンティティ、属性、関係、およびカーディナリティ表記。これらは図の構成要素となります。
- ERDを作成するための6つのステップ:エンティティの特定、属性の定義、関係のマッピング、カーディナリティの追加、設計の精緻化、そしてすべての記録
- 実例を用いたERDの作成方法:要件定義から完成図までのデジタル図書館システムの設計プロセスを完全解説
- MiroでERDを作成する方法:AIを活用した図解機能を使って、プレーンテキストの記述から初期構造を生成し、チームと共同で調整・改善します
- 効果的な図作成のためのベストプラクティス:ERDを明確かつ保守しやすいものにする命名規則、レイアウト戦略、およびドキュメント作成基準
- 避けるべきよくあるミス:過度な複雑化や不適切な関連付けから、不適切なエンティティの特定やステークホルダーによる検証の欠如まで
今すぐ Miro を試す
Miro を活用して最高の成果を上げている、数千ものチームの仲間に加わりましょう。
複数のツールに散らばったドキュメントを同期させようと何時間も無駄にするのはやめましょう。データベース構造が誰も更新しない静的な文書に存在する場合、チームは結局、古い前提に基づいて構築することになる。これは高コストな手直し作業と整合性の取れていない実装につながります。エンティティ・リレーションシップ図は、データの接続関係を正確に可視化する単一の信頼できる情報源を構築することでこの問題を解決し、データベース設計を迅速かつエラーの発生しにくいものにします。
エンティティ・リレーションシップ図(ERD)とは何ですか?
エンティティ・リレーションシップ図(ERD)とは、データベース内の異なる情報の断片が互いにどのように関連しているかを視覚的に示す表現である。データ構造の設計図と考えてください。エンティティ(「顧客」や「注文」など)、それらの属性(「メールアドレス」や「注文日」など)、およびそれらの間の関係(「顧客は複数の注文を行う」など)を表示します。ERDはビジネス要件と技術的実装の間のギャップを埋めるものであり、開発者とステークホルダーの双方に、データがシステム内をどのように流れるかを明確に示す。
エンティティ・リレーションシップ図の理解
エンティティ・リレーションシップ図は、抽象的なデータ要件を具体的な視覚的モデルに変換し、データベース実装を導くものである。本質的に、ERDは次の3つの基本的な問いに答えるものです:システムにはどのような情報を保存する必要がありますか?その情報はどのように整理されていますか?では、異なる情報の断片は互いにどのように結びついているのでしょうか?
中核的な目的:データベース構造と関係性の可視化
ERDは、ビジネス要件と技術的実装の間のコミュニケーション層として機能する。プロダクトマネージャーが「顧客の購入履歴を追跡する必要がある」と言うとき、ERDはその要件を具体的なエンティティ(顧客、注文、製品)、それらの属性(顧客ID、注文日、製品名)、そしてそれらを結びつける関係性(顧客が注文を行う、注文が製品を含む)に変換します。
この視覚的フォーマットは、コードの一行も記述される前に設計上の欠陥を捕捉します。提案した構造では、複数の配送先住所を持つ顧客に対応できないことが判明したり、商品のバリエーションを追跡するために、想定していなかった追加のエンティティが必要になることに気づくかもしれません。
ERDを使用するタイミングと理由
単一セッションを超えて永続化が必要な構造化データを扱う際には、ERD(エンティティ関係図)を使用してください:
新しいプロジェクトの開始:データベーススキーマやAPI仕様書を作成する前に、ERDを使ってデータモデルを整理しておきましょう。これにより、開発の途中で構造が主要な機能をサポートできないと気づいた際に生じる、苦痛を伴うリファクタリングを防ぐことができます。
主な機能の計画:SaaS製品にマルチテナント機能を追加しますか?レコメンデーションエンジンの実装?これらの機能は、データモデルに大幅な変更を必要とすることが多い。ERDを使用すれば、特定の構造に決定する前に、異なる構造的アプローチをテストできます。
新入社員の受け入れ:適切に文書化されたERDは、導入期間を大幅に短縮します。新規エンジニアは、テーブル定義や結合クエリから断片的に組み立てる必要がなく、データアーキテクチャ全体を一目で把握できます。
ステークホルダーとのコミュニケーション:技術に詳しくない関係者でも、データベースのスキーマは理解できないかもしれませんが、ERDなら理解できるでしょう。これにより、設計レビューや要件検証の生産性が大幅に向上します。
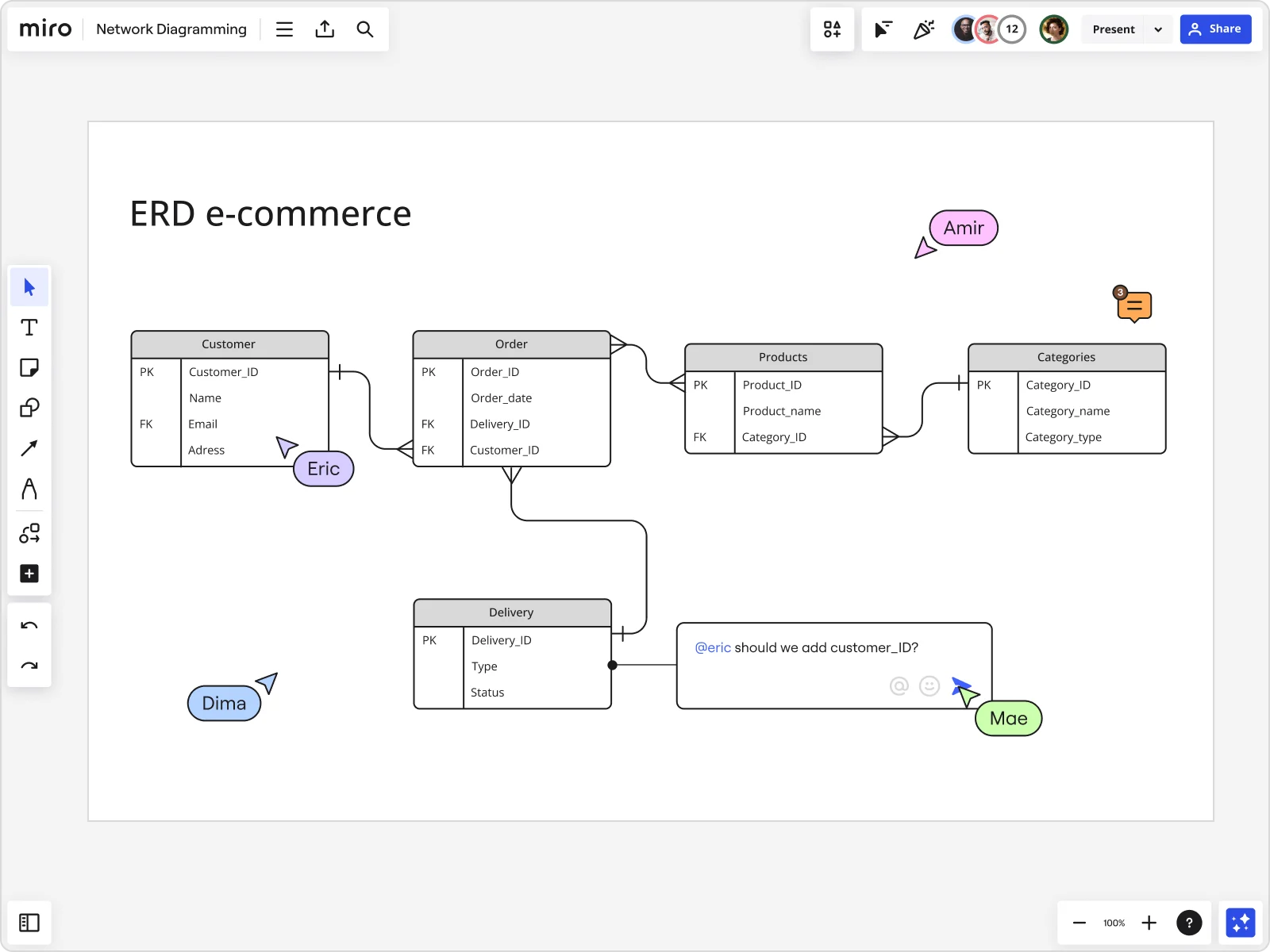
ERDの主要構成要素
すべてのエンティティ・リレーションシップ図は、データ構造を表現するために連携して機能する4つの基本構成要素から成り立っています。
エンティティ
エンティティは、システムが追跡する中核概念です。それらは、データが関連付けられている「もの」である。電子商取引システムにおけるエンティティには、顧客、商品、注文、カテゴリが含まれる。図書館システムでは、Book(書籍)、Member(会員)、Loan(貸出)があります。
エンティティを、複数の情報で記述する必要がある、独立した概念を表す名詞と考えてください。各エンティティはデータベース内のテーブルとなります。エンティティは通常、長方形として描画され、その上部にエンティティ名が記載される。
命名規則:各エンティティはその概念の1つのインスタンスを表すため、名詞は単数形(Customer、Customersではない)を使用してください。
属性
属性とは、エンティティを記述する個々のデータ要素である。顧客エンティティの場合、属性にはcustomer_id、first_name、last_name、email、phone_numberなどが含まれる可能性があります。これらの属性はデータベーステーブルの列になります。
すべてのエンティティには、各インスタンスを一意に識別する特別な属性である主キーが必要です。主キーにより、たとえ同じ名前であっても、2人の顧客を区別できるようになります。主キーは通常、ERD図において「PK」と表記されるか、下線が引かれる。
属性はエンティティ名の下、エンティティの矩形内にリスト表示されます。
人間関係
関係は、エンティティが互いにどのように接続されるかを定義する。これらは、「顧客は注文とどのように関わっているのか」や「商品とカテゴリーの間にはどのような関係があるのか」といった疑問に答えるものです。
関係はエンティティを結ぶ線で表され、しばしばその関係を説明する動詞が付随する:
- お客様が注文する
- この商品は以下のカテゴリに属しています
- 従業員が従業員を管理する
データベースでは、リレーションシップは外部キーを通じて実装されます。これらは、あるテーブル内の属性であり、別のテーブルの主キーを参照するものです。
カーディナリティ
カーディナリティは、あるエンティティのインスタンスが別のエンティティのインスタンスと関連付けられる数を規定する。関係線の端にある記号を用いて示される。
マンツーマン(1対1):エンティティAの各インスタンスは、エンティティBのちょうど1つのインスタンスと関連付けられます。例:各従業員には、会社のノートパソコンが1台支給されます。両端に「1」を表示するか、単一の縦線で示す。
1対多(1:N):エンティティAの各インスタンスは、エンティティBの複数のインスタンスと関連付けられますが、各Bは1つのAのみと関連付けられます。例:1人の顧客が複数の注文を行います。一端に「1」が示され、他端にはカラス足(三叉のフォーク)または「N」が示される。
多対多(M:N):どちらのエンティティのインスタンスも、もう一方のエンティティの複数のインスタンスと関連付けられる。例:学生は複数のコースに登録し、コースには複数の学生が在籍しています。両端にカラスの足跡または「N」が表示されています。これらを実装するには結合テーブルが必要です。
エンティティ、属性、関係、カーディナリティという4つの構成要素を理解することで、エンティティ・リレーションシップ図を効果的に読み、作成し、議論するための語彙が身につきます。
ERD図を作成する利点
エンティティ・リレーションシップ図の作成は、チームがデータ駆動型システムを設計、構築、維持する方法に具体的な改善をもたらします。
データベースの計画と最適化
慎重に設計されたERDは、最もコストのかかる技術的負債——修正に大規模なリファクタリングを必要とする根本的な構造的問題——を防止する。実装前にエンティティと関係を設計図として描くことで、コードを書かずに異なる構造的アプローチをテストできます。
ERDは正規化の問題を早期に明らかにする。同じ顧客の住所を3つの異なるテーブルに保存していることに気づくかもしれません。あるいは、提案された構造では、単純な操作を行うだけでも複雑なクエリが必要になってしまうことに気づくかもしれません。これらの問題を図上で修正するのに数分しかかかりません。数百万件のレコードを含む本番データベースのリファクタリングには数日を要し、現実的なリスクを伴う。
チームコミュニケーションと方向性の統一
視覚的な補助なしのデータベース設計の議論は、すぐに混乱に陥る。ERDは、全員に同じ視覚的参照点を与えることで、この曖昧さを解消します。
クロスファンクショナルチームにとって、この明確さは不可欠である。プロダクトマネージャーは、データモデルが計画された機能をサポートしていることを確認できます。デザイナーは、インターフェースに表示可能な情報が何であるかを確認できます。QAエンジニアはエンティティ間の関係に基づいてテストシナリオを計画できます。
開発上のエラーとコストの削減
研究では一貫して、設計段階で発見されたバグは実装段階で発見されたバグよりも修正コストがはるかに低く、本番環境で発見されたバグよりもさらに低いことが示されている。ERDは開発ライフサイクルの早い段階でエラーを発見するのに役立ちます。
ERDが防止するよくある高コストな誤り:
- 欠落している関係:導入の途中で、顧客と契約プランを紐付ける方法がないことに気づく
- 循環依存関係:テーブルAがテーブルBに依存し、テーブルBがテーブルCに依存し、さらにテーブルCがテーブルAに依存するようなエンティティ構造を作成する
- データの重複:同じ情報を複数の場所に保存すると、更新の不整合が生じます
- ビジネスルールに対するサポートが不十分:技術的には機能するが、ビジネス上の制約を適用できない仕組みを構築する
前提条件:始める前に必要なもの
効果的なエンティティ・リレーションシップ図を作成するには、適切な情報を収集し、適切なツールを設定する必要があります。
要件収集チェックリスト
エンティティとリレーションシップの描画を始める前に、以下の情報を収集してください:
- 業務要件書:このシステムにはどのような機能が必要ですか?どのような情報を追跡する必要があるか?
- 既存のデータソース:既存のシステムを再設計する場合は、サンプルデータをエクスポートし、現在のデータベーススキーマを確認してください
- ユーザーのワークフロー:システム内でユーザーが実行する主な操作を整理する
- データ量の推定値:各エンティティにはいくつのレコードが含まれますか?
- コンプライアンスおよびプライバシーに関する要件:どのようなデータに特別な保護が必要ですか?
ステークホルダーの特定
効果的なERDの作成は単独で行う活動ではない。以下の関係者を巻き込む:
- 各分野の専門家:あなたがモデル化しようとしている事業分野を深く理解している人々
- エンドユーザー:このシステムを日常的に利用する方々
- データベース管理者:彼らはパフォーマンス最適化に関する専門知識を持っています
- バックエンドエンジニア:彼らはERDを実際のデータベーススキーマとして実装する
- プロダクトマネージャー:彼らは、データモデルが製品ロードマップに対応していることを確認します
単独で設計して後からフィードバックを求めるのではなく、共同作業セッションをスケジュールする。リアルタイムの議論では、疑問や問題点が即座に提起される。
ER図の描き方:例を交えた順を追った解説
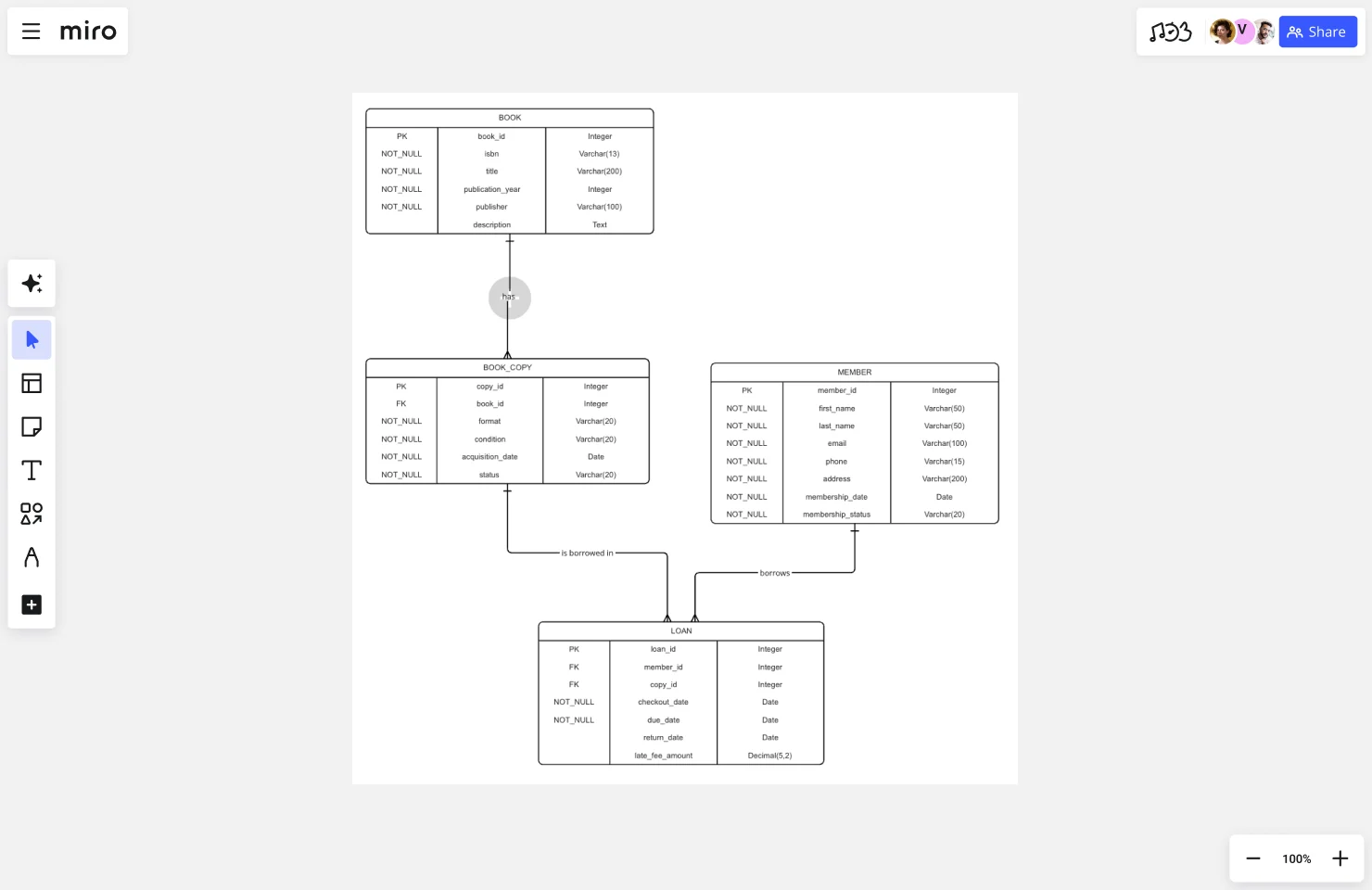
デジタル図書館システムを構築しながら、完全なエンティティ・リレーションシップ図の作成手順を順を追って説明しましょう。この実践的な例では、プロセスの各ステップを実演します。
シナリオ
公共図書館向けに、蔵書と会員活動の追跡方法を近代化するためのシステムを設計しています。図書館は以下を行う必要があります:
- 書籍の在庫を管理する(同一タイトルの複数冊を含む)
- 図書館会員とその連絡先情報を追跡する
- 会員が本を借りたり返却したりした記録
- 延滞しているアイテムを特定し、延滞料金を計算する
ステップ 1:エンティティを特定する
エンティティは、システムが追跡する必要がある中核概念を表します。まず要件を確認し、情報を保存する必要があるものを表す名詞をすべてハイライトします。
当図書館システムでは、以下の点を特定しています:
- 書籍:図書館の所蔵資料のタイトルを表します(例:「アラバマ物語」)
- 書籍紹介文:個々の物理的またはデジタルな実体を表します(図書館には、同じ書籍のハードカバー版が3冊所蔵されている場合があります)
- メンバー:資料を借りることができる図書館利用者を指す
- ローン:会員がBookCopyを借り出す際の貸出取引を表します
- 著者:著者の代理を務める
- カテゴリ:主題分類(小説、歴史、科学)を表す
なぜ「Book」と「BookCopy」を区別するのですか?これは、いわゆる「製品と在庫」の区別です。もし書籍エンティティが1つだけなら、物理的なコピーごとにタイトル、著者、ISBNを複製する必要がある。それらを分離すると、共通データは1か所(Book)に存在し、インスタンス固有のデータ(状態、ステータス)はBookCopyに存在します。
エンティティを特定する際に確認すべき事項:
- このシステムが扱う主な主題は何ですか?
- ユーザーはどのようなものを作成、更新、または削除しますか?
- ユーザーは何を検索したり、レポートを生成したりしたいと思うでしょうか?
避けるべきよくある間違い:単なる属性に過ぎない概念のためにエンティティを作成してはいけません。「住所」は独立したエンティティのように見えるかもしれませんが、常に特定の顧客に関連付けられ、独立した存在を持たない場合、顧客(Customer)内の属性(通り、市、州、郵便番号)としてモデル化した方が適切です。
ステップ 2:各エンティティの属性を定義する
エンティティを特定したら、それぞれについて保存する必要がある情報を決定します。各エンティティについて、ユーザーが知る必要のある情報をすべて列挙してください。
書籍:
- book_id (主キー)
- ISBN
- タイトル
- 出版年
- 出版社
- 概要
書籍紹介文:
- copy_id(主キー)
- book_id (Book への外部キー)
- 形式(ハードカバー、ペーパーバック、電子書籍)
- 状態(良好、普通、やや劣る、劣る)
- 取得日
- 状態(利用可能、貸出中、破損)
メンバー:
- member_id (主キー)
- 名, 姓
- メールアドレス、電話番号、住所
- 会員加入日
- メンバーシップステータス(有効、停止中、期限切れ)
ローン:
- ローンID(主キー)
- copy_id(BookCopyへの外部キー)
- member_id(メンバーテーブルへの外部キー)
- チェックアウト日, 支払期日
- 返却日(未返却の場合はnull)
- 延滞料金額
著者:
- author_id (主キー)
- 名, 姓
- 生年
- 国籍
カテゴリ:
- category_id(主キー)
- カテゴリ名
- 概要
主キーの解説:どのエンティティにも、各インスタンスを一意に識別する属性である主キーが必要です。主キーは一意(重複がないこと)、NULL不可(すべてのインスタンスに値が設定されていること)、かつ不変(時間の経過とともに変更されないこと)である必要があります。自動増分される整数を使用しています(customer_id:(1、2、3…)と簡略化します。
属性の種類:
- 単純な属性には単一の値が含まれます(first_name、price、registration_date)
- 複合属性は、より小さな要素に分解することができます(住所を「通り名」「市名」「州名」「郵便番号」に分解するなど)
- 派生属性は、他の属性から計算することができます(例:birth_date から age を算出する)
ステップ 3:エンティティ間の関係をマッピングする
関係は、エンティティが互いにどのように接続されるかを定義する。ユースケースにおけるエンティティの相互作用を検証することで、それらを特定する。
当図書館システムについて:
書籍からBookCopyへ:1対多。1冊の本(タイトル)には多くの本のコピー(物理的な実体)がありますが、各本のコピーは1冊の本に属します。これにより、タイトルレベルでの共通情報を維持しながら、個々のコピーを追跡することが可能になります。
「貸出用」にコピー:1対多。1つの書籍コピーは複数の貸出(その存続期間中に複数回借りられる)に現れることができますが、各貸出には1つの書籍コピーが関与します。これは各物理アイテムの貸出履歴を追跡します。
会員から融資へ:1対多。1人の会員は複数のローン(時間をかけて複数のアイテムを借りる)を持つことができますが、各ローンは1人の会員に属します。これにより、各利用者の貸出履歴が得られます。
著者の本:多対多。1冊の本には複数の著者(共著作品)がおり、1人の著者は複数の本を書きます。この関係を実装するには、BookAuthor という結合テーブルが必要であり、book_id と author_id を外部キーとして設定します。
カテゴリ別書籍:多対多。1冊の本は複数のカテゴリに属することができ(『オデッセイ』はSFと冒険小説の両方のカテゴリに分類される可能性がある)、各カテゴリには複数の本が含まれています。BookCategory 結合テーブルを作成します。
なぜ独立したローン事業体が必要なのでしょうか?ローンとは、単なる関係性ではなく、時間軸に基づく事象を捉えるものです。現在誰が本を所持しているかだけでなく、過去に誰が借りたか、返却期限はいつか、延滞料金が発生したかといった完全な履歴も把握する必要があります。各貸出処理は新しい貸出記録を作成し、履歴記録を構築します。
カーディナリティの理解:
適切なカーディナリティを決定するために、具体的な例を順を追って検討する。顧客から注文へ:
- 1人の顧客が複数の注文を持つことは可能ですか?はい。
- 1つの注文が複数の顧客に属することは可能ですか?いいえ(通常は)。
- したがって:一対多の関係。
製品カテゴリ別:
- 1つの製品が複数のカテゴリに属することは可能ですか?はい(事業内容によって可能です)。
- 1つのカテゴリに複数の商品を登録できますか?はい。
- したがって:多対多の関係。
ステップ 4:カーディナリティ表記を追加する
カーディナリティ表記は、ERD上で関係の多重性を明示的に示すことで、各関係に何個のエンティティが参加できるかについての曖昧さを解消します。
視覚的表現:
1対1の関係の場合は、関係の両端に「1」または縦線を1本ずつ記入してください。
「1対多」の場合、「1」を「1」と表記し、「多」の側には「N」、「M」、または三つ又の記号(三本足のフォーク)を記します。Book-to-BookCopyの関係において、Bookの近くに「1」を、BookCopyの近くにカラス足(✧)を配置してください。
多対多の関係の場合は、両側に「N」または「カラス足」のマークを付けます。この関係性を実装するには、結合テーブルを作成する必要があることを覚えておいてください。書籍と著者の関係は両端にカラスの足跡(シワ)を示し、書籍と著者の結合テーブルがこの接続を実装している。
基数表記は、それが表すエンティティの近くに配置し、関係線は明確で整理された状態を保つこと。可能な限り、エンティティの配置を再調整して線交差を回避してください。
ステップ 5:図を精査し、検証する
初期のERDが完成したら、一歩引いて批判的に評価してください。この精緻化フェーズでは、実装前に構造上の問題を捕捉します。
正規化チェック:
- 第一正規形(1NF):各属性には、リストや集合ではなく、単一の値のみを含める必要があります。会員が複数の電話番号を所有している場合、それらを「555-1234, 555-5678」のように1つのフィールドに保存しないでください。代わりに、別のMemberPhoneエンティティを作成してください。
- 第2正規形(2NF):キーではないすべての属性は、主キー全体に依存する必要があります。OrderItemエンティティに複合キー(order_id、product_id)が設定されている場合、product_nameをOrderItemに保存しないでください。product_nameはproduct_idのみに依存するからです。Productエンティティにproduct_nameを保持する。
- 第3正規形(3NF):属性は主キーのみに依存すべきであり、主キー以外の属性には依存すべきではない。zip_codeも保存する場合は、Addressエンティティにcityとstate_nameの両方を保存しないでください。州は郵便番号から推測できます。
検証チェックリスト:
- すべてのエンティティには主キーがありますか? ✓
- すべての関係は必要であり、正しく定義されているか? ✓
- カーディナリティ表記は正確か? ✓
- 構造は必要なすべてのクエリをサポートできますか? ✓
- 多対多の関係で結合テーブルが必要なものはありますか? ✓
査読プロセス:
関係者とERDを共有する:
- 各分野の専門家が、モデルがビジネス上の概念やルールを正確に反映していることを確認する
- データベース管理者は、技術的な実現可能性とパフォーマンスへの影響について検討する
- 同僚のエンジニアが、内容の網羅性とエッジケースを確認します
主要なワークフローに対してデザインをテストする:
決済の流れ:会員がカードをスキャン → システムが会員レコードを検索 → 司書が本をスキャン → システムが図書レコードを検索 → システムが貸出記録を作成する。必要なデータはすべて揃っています。✓
著者名で本を検索する:システムはBookAuthor結合テーブルをクエリし、そのauthor_idに対応するすべてのbook_idを取得し、Bookテーブルと結合してタイトルを取得します。構造はこのクエリを効率的にサポートします。✓
延滞通知:「return_date が NULL かつ due_date が今日より前の」貸出データを照会し、連絡先情報を取得するために Member テーブルと、アイテムの詳細情報を取得するために BookCopy および Book テーブルと結合する。すべてのデータにアクセス可能。✓
手順 6:記録して共有する
適切な文書化がなされていないERDは、時間の経過とともに解釈が困難になる。図が有用であり続けることを保証する文脈を追加してください。
注釈の追加:
以下の要素をERD上に直接、または付属文書に記載してください:
- エンティティの説明:「BookCopy:」「書籍のタイトルごとに、物理的またはデジタル上の個々の実体を表し、特定のアイテムの所在、状態、および貸出履歴を追跡できるようにします。」
- 関係制約:「注文は同一サプライヤーの製品のみを参照できる」— 単なるカーディナリティだけでは表現できないビジネスルール。
- 属性の制約:「discount_percentage は 0 から 100 の間でなければならない」または「status は pending、processing、shipped、delivered のいずれかでなければならない。」
- 設計上の決定事項:「購入時に製品名が変更または削除されても、その名称を保持するため、product_nameをOrderItemに非正規化することを選択しました。」
エクスポートと共有:
ERDを必要とするすべての人々がアクセスできるようにしてください。異なる対象者向けに適切な形式でエクスポートする — 技術チームはスキーマ定義言語を好む一方、非技術的な関係者はPNGやPDFなどの視覚的フォーマットを必要とする。
ERDを関連文書にリンクする。要件定義書、API仕様書、実装コードと関連付け、ビジネス要件からデータモデルを経て実際の実装に至るまでの流れを追跡できるようにする。
バージョンの管理:
ERDを生きている文書として扱ってください:
- ERDソースファイルには、コードと同様にバージョン管理を使用してください
- データベース変更を実施する際はERDを更新する — 開発者が新しいテーブルを追加する場合、その作業の一環としてERDを更新すべきである
- 定期的なERDレビュー(四半期ごと、または主要機能の計画時)を実施し、それが依然として現実を反映していることを確認する
このライブラリのERDが実現するものは
この構造が整うことで、ライブラリは以下が可能となります:
- 最も人気のある書籍に関するレポートを生成する(貸出と書籍を結合し、出現回数をカウントする)
- 延滞通知を送信する(返却日がNULLかつ期限日が過ぎている貸出をクエリする)
- 交換が必要なコピーを追跡する(状態と貸出履歴でBookCopyを照会)
- 本を推薦する(会員の貸出履歴からカテゴリー一致を検索)
- 正確な延滞料を計算する(ローン内のdue_dateとreturn_dateを追跡する)
- 在庫を効率的に管理する(貸出頻度に基づいて追加購入が必要な書籍を確認する)
ERDは「書籍と貸出の追跡」といった抽象的な要件を、これら全てのユースケースをサポートする具体的で実装可能な構造へと変換する。
MiroでERDを作成する方法
ビジュアルコラボレーション・プラットフォームは、ERDの作成を、技術者一人で行う作業から、ステークホルダーがリアルタイムで参加するチーム活動へと変革します。Miroの革新的なワークスペースは、事前作成済みテンプレート、AIによる自動生成、リアルタイムコラボレーションを組み合わせ、ERDの作成をより迅速かつ協働的に行えるようにします。
ERD作成にMiroを使う理由
リアルタイムでの共同作業:複数のチームメンバーが、同じERDを同時に編集します。ドメインエキスパートは、エンジニアが関係性を描いた瞬間にそれを明確化できる。プロダクトマネージャーは、エンティティが具体化するにつれて、構造が計画された機能をサポートしていることを確認する。
AIを活用した迅速なスタート:データベースの要件を平文で記述し、Miro AIに初期構造を生成させましょう。各エンティティごとに手動でボックスを作成する代わりに、洗練と検証に集中します。
視覚的文脈の処理:Miro AIは、ボード上の既存のブレインストーミングのメモ、要件、または付箋を分析し、それらを構造化されたERDのエンティティと関係に変換することができます。
すべてのステークホルダーが利用可能:視覚的で直感的な形式により、従来のデータベース表記法を理解できない技術に詳しくない関係者でも、ERDを容易に理解できるようになります。
MiroでERDを作成する:2つのアプローチ
選択肢1:MiroのAI ER図生成ツールによるAI生成の図
- Miro AI にアクセス:Miroボードを開き、「フォーマット」アイコンをクリックします
- 図の形式を選択してください:「書式」セクションから「図」または「マインドマップ」を選択してください
- 要件を記述してください:次のようなプレーンテキストの説明文を入力してください:「書籍、書籍の部数、図書館利用者、貸出、著者、およびカテゴリを管理する図書館システムのエンティティ・リレーションシップ図を作成してください。」書籍は複数のコピーと複数の著者を持ち得る。会員は複数の書籍を借りることができます。
- 確認と修正:Miro AIはエンティティと関係を生成します。フォローアッププロンプトを使用して調整してください:「BookとLoanを接続するBookCopyエンティティを追加する」または「BookとAuthorを多対多関係にする」
- 詳細な属性を追加する:各エンティティボックスをクリックして、主キー、外部キー、データフィールドなどの特定の属性を追加してください
プロのアドバイス:プロンプトを表示する前に、ボード上の既存の付箋や要件を選択してください。Miro AIはこの視覚的コンテキストを活用し、ユーザーの特定のニーズに基づいてより関連性の高い図を生成します。
選択肢2:テンプレートに基づく作成
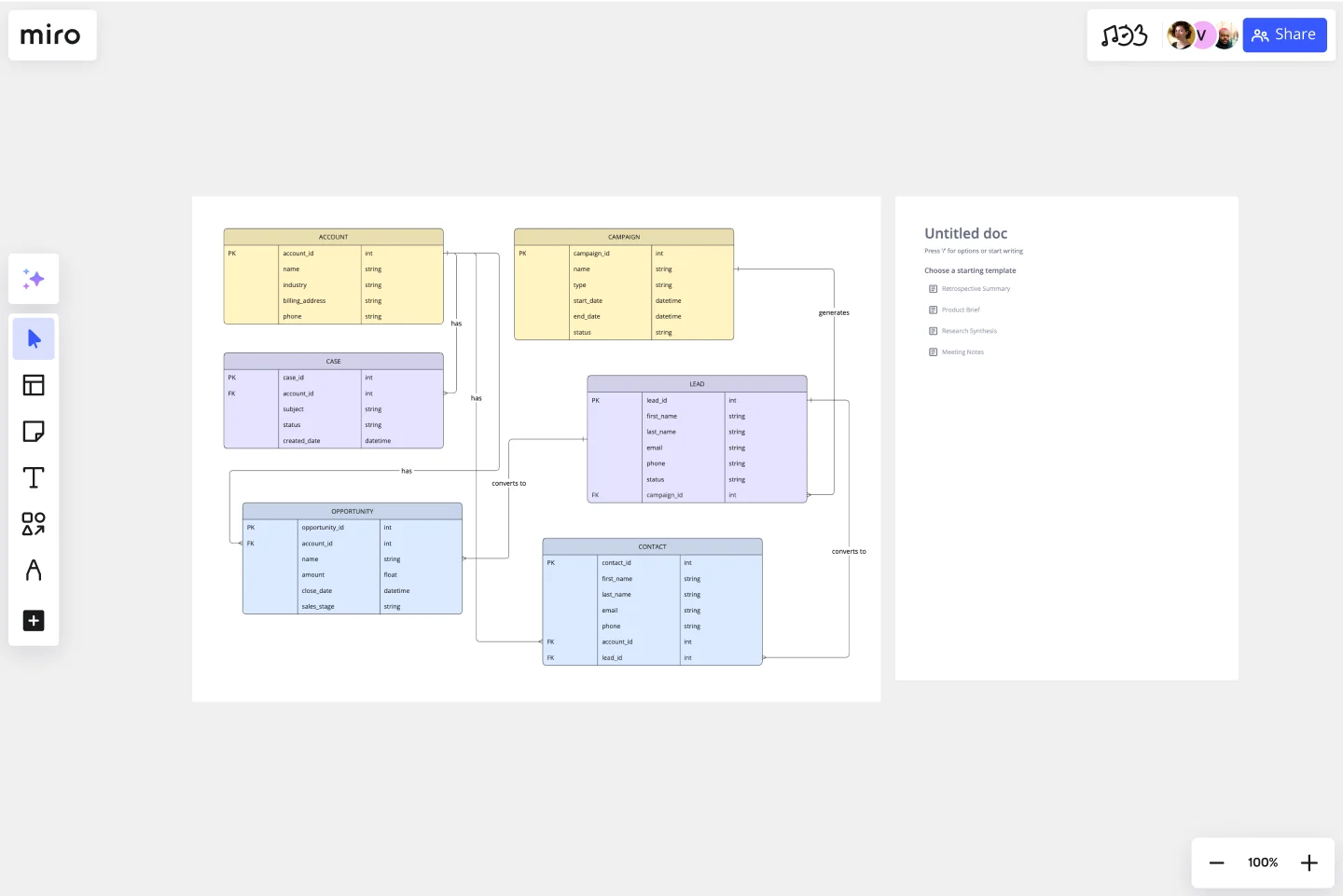
- ERDテンプレートを開きます:Miroのテンプレートライブラリで「エンティティ・リレーションシップ図」を検索する
- エンティティボックスのカスタマイズ:書式設定済みのエンティティボックスの名前を変更し、属性を追加する
- 関係性を描く:テンプレートコネクタを使用してエンティティをリンクし、カーディナリティ表記を追加します
- 結合テーブルを追加する:多対多の関係については、双方をつなぐ結合エンティティを作成します
共同による改良
基本的な構造が整ったら:
- 文脈を添えて注釈を付ける:設計上の判断について説明するテキストボックスを追加する
- 共同作業者を招待する:このボードをデータベース管理者、エンジニア、および各分野の専門家と共有してください
- 特定の要素についてコメントする:特定のエンティティや関係について意見が必要な場合は、@メンションを使ってチームメンバーに通知してください
- リアルタイムで反復処理を行う:チームメンバーが同時に参加し、一緒にデザインを練り上げるための作業セッションを設定する
Miroは、最終的なERDだけでなく、コメント、検討された代替案、選択の根拠に至るまで、設計に関する議論の全容を記録します。これにより、将来のチームメンバーがデータアーキテクチャの決定事項を理解するのに役立つ「生きているドキュメント」が作成されます。
効果的なER図を作成するためのベストプラクティス
適切に設計されたERDは、完全性と明瞭さのバランスを取っている。
明瞭性と簡潔性の原則
まずはシンプルに始め、その後複雑さを加えていく。中核となるエンティティと明らかな関係性から始めましょう。それらが検証されたら、エッジケースや特殊なエンティティを追加していく。ERDに15~20以上のエンティティが含まれる場合は、抽象度を高めるか、ドメインごとに分割して分割してください。
エンティティを詰め込まないでください。関係線には十分な余白を設け、カーディナリティ表記が明確に見えるようにしてください。グループを関連するエンティティごとにまとめ、グループ間に十分な間隔を空けてドメイン境界を視覚的に示す。
命名規則と標準
エンティティ名:名詞は単数形を使用してください(「Product」ではなく「Products」、「Order」ではなく「Orders」)。
属性:snake_case または camelCase を一貫して使用し、決して混在させないでください。説明的な名前を選択してください:「order_date」は「date」よりも明確であり、「product_price」は「price」よりも明確です。
人間関係:自然な読み方の動詞を使って、関係性を表現してください:「顧客が注文を行う」、「製品はカテゴリに属する」。関係名は、どちらの方向から読んでも意味が通じるようにすべきです。
主キー:一貫したパターンに従う。多くのチームは「エンティティ名_ID」(例:customer_id、order_id)を使用し、主キーを即座に認識できるようにしています。
外部キー:外部キーには、参照先が明確にわかるような名前を付けること。注文エンティティが顧客を参照する外部キーを持つ場合、その名前はcustomer_refやcustomer_fkではなくcustomer_idと命名してください。
レイアウトと構成の戦略
関連エンティティを互いに近接して配置し、関係線の長さを最小化し、交差を減らす。論理的な流れに従う — 適用可能な場合は、ワークフローやプロセスフローを反映するようにエンティティを配置する。図書館の例では、メンバー → 貸出 → 書籍コピー → 書籍という位置付けが貸出手続きを反映しています。
色を意図的に使う。エンティティをドメインごとに色分けする(在庫関連のエンティティはすべて青、顧客関連のエンティティはすべて緑)ことで、ドメイン境界を直ちに可視化する。やりすぎないでください——色が多すぎると気が散ります。
文書化基準
以下の文脈要素を追加してください:
- エンティティの説明:各エンティティが何を表し、どのような目的を持つかを一文で説明する
- 属性制約:ドキュメントの検証ルール、許容値、および計算ロジック(「late_fee_amount:(延滞日数 × 日額)として計算される)
- 関係の説明:明らかでない関係については、そのビジネス上の意味を説明してください(「なぜLoanはBookではなくBookCopyに関連付けられているのか?」(「どの実物の本が貸し出されたかを追跡する必要があるため」)
- 前提条件:設計に組み込まれている前提条件を文書化する(「各注文には配送先住所が1つだけあるものと仮定する。「複数の宛先への分割発送が必要になる場合は、この仕組みを見直す必要があります」)
ER図を作成する際のよくある間違い
これらの誤りを早期に認識することで、後々の大幅なリファクタリング作業を回避できる。
過剰な複雑化と機能の肥大化
間違い:初期のERDで考えられるあらゆる例外ケースや将来の機能を網羅しようとすると、数十ものエンティティが並ぶ肥大化した図になってしまい、その多くは実際には必要とされないものになってしまう。
解決策:まずは、現在の要件を満たす最小限の実用可能なデータモデルから始めましょう。実際にそれらを必要とする機能を作成する際に、エンティティとリレーションシップを追加してください。「YAGNI」(You Aren’t Gonna Need It)を実践しましょう。関係者が将来のシナリオを計画することを主張する場合、それらを初期のERDに実装するのではなく、「将来の検討事項」として別途文書化すること。
誤った関係マッピング
よくある例:
- 貸出記録を直接的な一対多の関係とする(貸出用複写を省略)、どの特定の複写が貸出されたかについて曖昧さを生じさせる
- 「多対多」の関係が必要な場面で「一対多」を使用すること(各「コース」には複数の「学生」が紐づいているため、「学生」と「コース」の関係を「一対多」としてモデル化することは不適切である)
- 冗長なリレーションシップの作成(注文が顧客に接続され、注文品目が注文に接続される場合、注文品目から顧客への個別のリレーションシップは不要)
解決策:両方向から質問を投げかけることで、カーディナリティを確認する。ドメインエキスパートと共に実世界のシナリオを歩む:「1つの商品が複数のカテゴリに属することは可能ですか?」「1つの注文が複数の顧客に属することは可能ですか?」
不十分なエンティティ識別
間違い:本来は属性であるべき概念に対してエンティティを作成したり、別個のエンティティが必要な場合に属性を作成したりすること。
例:
- 属性が適切な場合の実体:住所には独立した存在がなく、常に正確に1人の顧客に紐づいている場合、「Address」エンティティを作成する。代わりに、顧客内の住所属性を使用してください。
- 該当する場合、属性を指定してください:書籍に複数の著者がいる場合や、「この著者のすべての書籍」を検索する必要がある場合、「author_name」を単一のテキストフィールドとしてBookに保存すると失敗します。
解決策:次の質問をしてみてください:
- この概念は他の実体とは独立して存在するのか?
- 複数のインスタンスを追跡する必要がありますか?
- この概念について別途クエリやレポートを作成する必要はありますか?
いずれかに「はい」と答えた場合、それはおそらくエンティティです。すべて「いいえ」の場合、それはおそらく属性である。
不十分な正規化
よくある例:product_name、product_description、および product_price を OrderItem に直接格納すると、問題が生じます:
- 製品詳細が変更された場合、過去の注文には古い情報が表示されます
- その商品を含むすべての注文で同じデータが重複しています
- 製品情報について、唯一の真実の源は存在しません
解決策:別々の問題です。過去のデータ(購入時の価格)を現在のデータ(現在の製品詳細)とは別に保存する。正規化のルールに従い、冗長性を排除する:
- 1NF:繰り返しグループやカンマ区切りの値は含まない
- 2NF:部分的な依存関係はありません
- 3NF:推移的依存関係なし
ステークホルダーとの検証が不足している
間違い:ERDを孤立した状態で設計し、実装の段階で実際のビジネスルールと一致しないことに気づく。
例:各患者に1人の主治医がいると想定して医療システムを設計したものの、実装の過程で、患者が専門分野ごとに複数の主治医を持つ可能性があることが判明した。
解決策:実装前に、ドメインの専門家と協力してERDの妥当性を確認する:
- 主なユースケースを順を追って説明します:「患者が予約を入れる際、どのような情報が必要ですか?」
- 具体的な例を示す:「ドクターのデータを次のように保存します。スミスはジョンとジェーンの両方を治療している。これは現実と一致しているのか?
- エッジケースのテスト:「治療の途中で患者が医師から別の医師へ転院した場合、どうなるのでしょうか?」
専用のレビューセッションをスケジュールする — 単にERDをメールで送ってフィードバックを待つだけではいけない。
Miroで初めてのERDを作成する準備はできていますか?
エンティティ・リレーションシップ図は、抽象的なデータ要件を具体的で実装可能な構造に変換し、データベース設計を導くとともにチームの連携を保ちます。このガイドで概説した体系的なアプローチに従うことで——エンティティの特定と属性の定義から、関係性のマッピングとステークホルダーによる検証まで——プロジェクトのライフサイクル全体を通じて、高コストな構造的問題を未然に防ぎ、信頼性の高い参照文書として機能するERDを作成できます。
効果的なERD作成の鍵は、協働にある。エンジニア、プロダクトマネージャー、デザイナー、ドメインエキスパートがリアルタイムで協働すると、設計上の欠陥は実装段階ではなく即座に表面化する。AIを活用した図解機能を備えたビジュアルコラボレーション・プラットフォームは、全員が同じワークスペースにアクセスできるようにすることで、設計の決定が下されるその場で、誰もが貢献し、コメントを付け、検証できるようにします。また、初期の制作プロセスを迅速化することで、チームは機械的な設定作業ではなく、設計の洗練に注力できるようになります。
次のデータベース設計プロジェクトを始めましょう。共同作業スペースを開き、AIに要件を説明するか、あらかじめ用意されたテンプレートを使用し、関係者を集めてデザインを共同で精緻化し、検証し、文書化します。慎重なERD設計に費やした時間は、リファクタリングの削減、チーム間コミュニケーションの明確化、そしてユーザーが必要とする機能を実際にサポートするデータベースという形で、見返りをもたらします。
Miroのエンティティ関係図ツール、テンプレート、AI機能を活用して構築を始め、ビジュアルコラボレーションによってデータベース設計が単なる技術文書から、チーム全体の戦略的な足並みを揃えるものへとどのように変革されるかを体感してください。
エンティティ・リレーションシップ図に関するよくある質問
ERDとUMLクラス図の違いは何ですか?
ERDとUMLクラス図はどちらもエンティティとその関係を示すが、それぞれ異なる目的を果たす。ERDは純粋にデータ構造に焦点を当てています——どのような情報を保存する必要があり、それらがどのように関連しているかです。主にデータベース設計に使用されます。一方、UMLクラス図はオブジェクト指向ソフトウェア設計を表し、データ(属性)と振る舞い(メソッド/関数)の両方を含みます。データベーススキーマを設計する場合は、ERDを使用してください。アプリケーションクラスとその相互作用をモデル化する場合、UMLクラス図を使用してください。実際には、ERDエンティティはオブジェクト指向システムにおいて永続ドメインクラスに直接対応することが多い。
ERDの作成にはどれくらい時間がかかりますか?
所要時間はシステムの複雑さとチームの関与度によって異なります。5~10個のエンティティを持つ小規模アプリケーションの単純なERD作成には、関係者による検証を含めて1~2時間かかる場合があります。中程度の複雑さを持つシステム(15~25のエンティティを含む)は、通常、複数回のセッションにわたり4~8時間を要する。大規模な企業システムでは、特に既存データベースの文書化や複数チーム間の調整が必要な場合、数日から数週間を要することがあります。Miroの「Create with AI」のようなAI搭載ツールを使用すれば、テキストによる説明から初期構造を生成できるため、制作の初期段階にかかる時間を大幅に短縮でき、機械的な設定作業ではなく、細部の調整や検証に時間を割くことができます。
技術者でない人もERDを作成できますか?
はい、特にERDの作成をより手軽に行えるビジュアルコラボレーションツールがあればなおさらです。技術に詳しくない人でも、正規化や外部キーといったデータベースの概念をすべて理解できなくても、エンティティ(システムが追跡する主要な「もの」)を特定し、属性(それらのものに関する情報)を列挙し、関係性(ものがどのようにつながるか)を説明することは十分可能です。ドメインエキスパートは、ビジネスルールやワークフローを深く理解しているため、最も正確なERDを作成することが多い。重要なのは、非技術的なドメイン知識と、構造がデータベース設計原則に従うことを保証できるエンジニアやデータベース管理者からの技術的ガイダンスを組み合わせることである。
論理ERDと物理ERDの違いは何ですか?
論理ERDは、特定のデータベースシステムに依存しない情報の構造を示す。これらはエンティティ、属性、主キー、および関係を含みますが、データ型、インデックス、またはデータベース固有の制約といった実装の詳細は指定しません。物理ERDは、データベースが特定のシステム(PostgreSQL、MySQL、Oracle)でどのように構築されるかを正確に示します。これにはテーブル名、列のデータ型(VARCHAR(255)、INTなど)、インデックス、制約、およびプラットフォーム固有の機能が含まれます。論理ERDから始めて構造を正しく設計し、実装準備が整ったら物理ERDを作成する。この分離により、データモデル全体を再設計することなく技術的な実装を変更できます。
ERDはどのくらいの頻度で更新すべきですか?
ERDはデータベースと共に進化する生きている文書であるべきです。データベースの構造変更(テーブルの追加、リレーションシップの変更、キー属性の変更など)を行うたびに、ERDを更新してください。ERDの更新を開発プロセスの一部として扱い、別個の文書化作業とは見なさないでください。開発者が新しいテーブルを追加する際には、同じワークフロー内でERDを更新すべきである。成熟したシステムについては四半期ごとのERDレビューをスケジュールし、ドキュメントと実装の間のずれを捕捉する。古いERDは、新しいチームメンバーを誤った方向に導き、開発中に誤った仮定を生むため、ERDがない状態よりも悪い。
AIはエンティティ・リレーションシップ図の作成を支援できますか?
はい、AIはERDの作成を大幅に加速できます。AI搭載ツールは、要件の平文記述から初期ERD構造を生成でき、エンティティボックスや関係線の作成といった機械的な作業の時間を節約します。システムが追跡すべき対象を記述すると、AIがエンティティとその関連性を示す初期図を生成します。AIはまた、ボード上の既存のブレインストーミングメモや要件定義書などを分析し、構造化された図表に変換することもできます。ただし、AIによって生成されたERDには、人間による確認と修正が必要です。つまり、関係性がビジネスルールに合致しているかを確認するドメインエキスパート、技術的な妥当性を保証するエンジニア、そしてその構造が計画された機能をサポートしているかを確認するステークホルダーが依然として必要となります。
ERDを描くには特別なソフトウェアが必要ですか?
いいえ、必要に応じて様々なツールでERDを作成できます。Miroのようなビジュアルコラボレーションプラットフォームは、部門をまたぐステークホルダーとのチームベースのデザイン作業に最適です。アクセスしやすく、リアルタイムでの共同作業が可能で、専門的な技術知識も必要ありません。従来のデータベース設計ツールはスキーマ生成や検証といった高度な機能を提供しますが、習得がより困難です。一般的な図作成ツールやホワイトボードでも、シンプルなERDを作成するには十分です。最高のツールとは、チーム全員がアクセスして利用できるものです。初期段階のデザインとステークホルダーの検証においては、協働とアクセシビリティを優先する。技術的な実装においては、精度とスキーマ生成機能を優先する。
ERDはどの程度詳細にすべきですか?
ERDの詳細は、プロジェクトのフェーズと対象者によって異なります。ステークホルダーとの初期段階の議論で使用される概念的なERDには、主要なエンティティと大まかな関係のみが示されています。これにより、技術に詳しくない参加者にも負担をかけずに、ビジネス要件の妥当性を確認するのに十分な情報が提供されます。論理ERDは全ての属性、主キー、完全な関係の詳細を追加するが、データベースに依存しない。物理ERDには、データ型、インデックス、制約、およびプラットフォーム固有の機能を含む、すべての実装詳細が含まれます。コアエンティティと明らかな関係性からシンプルに始め、理解が深まるにつれて複雑さを加えていく。初期のERDであらゆる例外ケースを網羅しようとしないこと——実装過程で詳細が明らかになる。適切な詳細レベルとは、ステークホルダーの合意形成、技術設計、データベース実装など、現在のタスクを遂行するのに役立つレベルを指します。
著者:Miroチーム
最終更新日:2025年12月12日