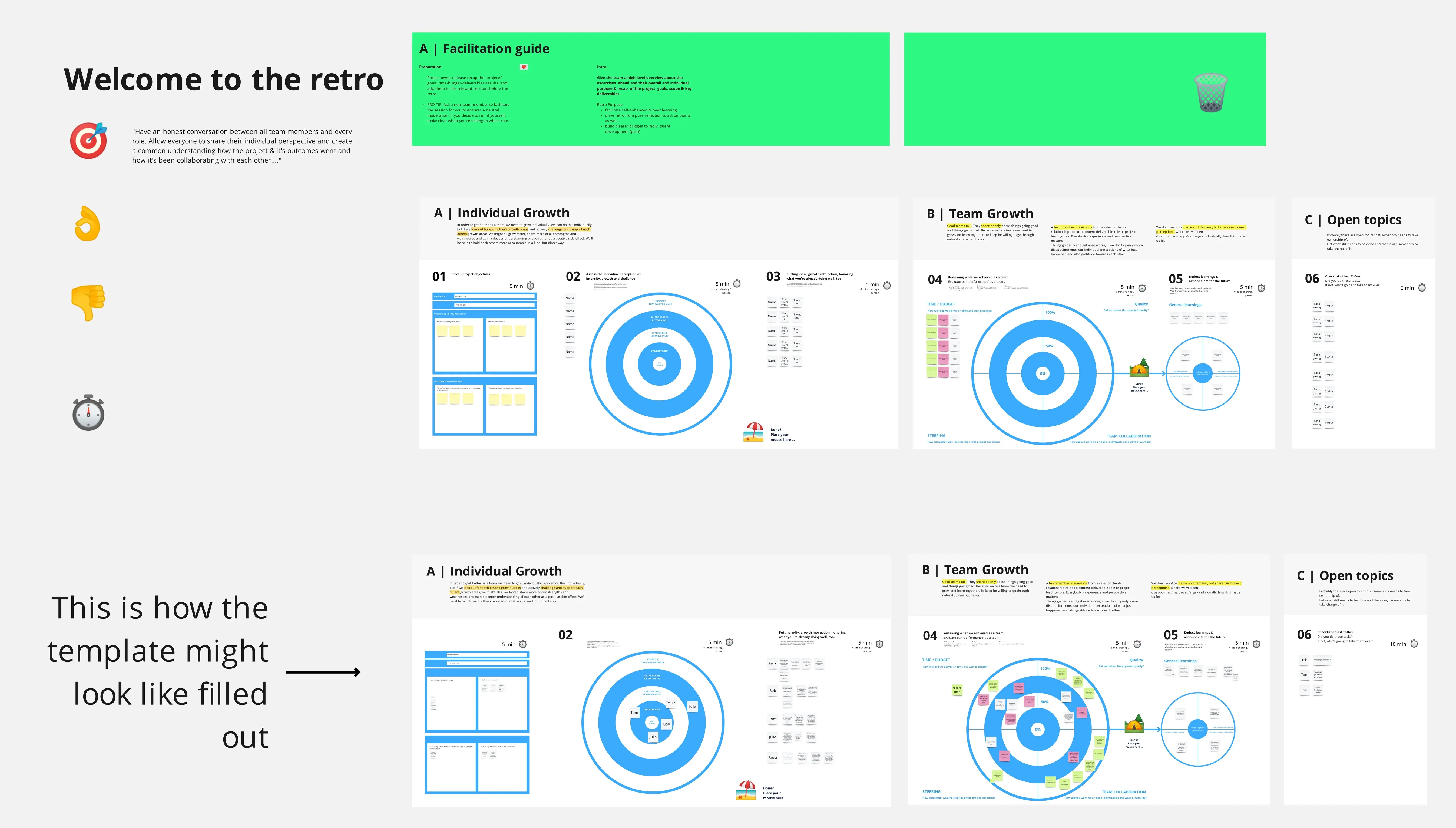
✅ Canevas de Clarté -L'approche Miro pour lemodèle de décomposition à quatre facteurs pour les estimations)
Ce modèle nous aide à évaluer la préparation et à estimer plus précisément en regardant au-delà de la taille et en comprenant ce qui pourrait nous ralentir.
Écrivez la description et les critères d'acceptation de l'histoire. Sans cela, nous ne démarrons même pas l'histoire. Vous décomposez chaque histoire en :
🔗 1. Dépendances
Cette histoire dépend-elle d'une autre équipe ?
Ou d'une autre histoire ?
Ou d'attendre un design / API / environnement ?
Exemple de notation :
0 = aucune
1 = petite dépendance (interne, facile)
2 = dépendance modérée
3 = dépendance externe (plateforme, fournisseur, autre équipe)
🚧 2. Bloqueurs
Y a-t-il quelque chose qui empêche même de commencer cette histoire ?
Quelque chose que l'équipe ne peut pas résoudre pendant le sprint ?
Notation :
0 = aucun bloqueur
2 = bloqueur potentiel
3 = bloqueur actif
⚠️ 3. Risques
Y a-t-il une chance que cela ne fonctionne pas comme prévu ?
Touche-t-il à des zones sensibles du code ?
Y a-t-il des implications de performance ou de sécurité ?
Notation :
0 = aucun risque
1 = risque à faible impact
2 = risque moyen
3 = élément à haut risque
❓ 4. Inconnus
Avons-nous des incertitudes quant à l'implémentation ?
Des explorations ou des tests nécessaires ?
Manquons-nous de clarté sur les critères d'acceptation ?
Évaluation :
0 = rien d'inconnu
1 = faible incertitude
2 = quelques investigations nécessaires
3 = incertitude majeure / critères d'acceptation peu clairs
📊 En Résumé : « Story Readiness Score »
Pour chaque histoire, l'équipe remplit une grille à 4 volets et attribue des scores.
Puis le score total =
Dépendances + Risques + Inconnues + Bloqueurs
Exemple :
Dépendances → 3
Inconnues → 1
Risque → 0
Bloqueur → 3
Total = 7
🚦 Le feu de signalisation « Sprint-Readiness »
Utilisez le score total pour décider rapidement de la préparation de l'histoire :
🟩 0–3 → PRÊTE à intégrer dans le sprint
Les histoires sont simples, à faible risque, faibles dépendances.
🟨 4–6 → À RÉVISER avant de s'engager
Ces éléments nécessitent une discussion :
Pouvons-nous réduire les dépendances ?
Pouvons-nous le découper ?
Pouvons-nous éliminer les inconnues avant de l'inclure ?
🟥 7+ → PAS PRÊT (nécessite un affinement)
Cette histoire pose problème.
Vous observerez généralement :
Trop de dépendances
Des inconnues qui sont en fait des blocages
Des clarifications manquantes
Cela garantit que votre équipe cesse d’intégrer des histoires risquées dans le sprint et les affine d'abord correctement.
💡 Par exemple
Nous avons 3 dépendances mais 1 inconnue qui est un blocage → probablement l'histoire ne peut pas être incluse dans le sprint.
Converti au modèle :
Dépendances = 3
Inconnue = 3 (inconnue = blocage)
Risque = peut-être 0
Blocage = 3
Total = 9 →
🟥 ROUGE → pas prêt.
🔥 Pourquoi cela fonctionne
Rend l'estimation objective
Aide l'équipe à dire « non » aux histoires peu claires
Réduit les surprises en cours de sprint
Aide le PO à savoir exactement ce qu'il faut corriger
Transforme le raffinement en une conversation guidée par les données, et non en jeu de devinettes