
How can organizations deploy AI agents safely at scale?
We’ve reached a point where almost anybody can create their own AI agent or automation. That’s great for experimentation, but a major headache for IT and security leaders.
The question CISOs are grappling with is how to give people the tools to explore agents and agentic workflows while making sure they don’t inadvertently break the law or breach data processing agreements.
It’s a problem we ran into at Miro. We knew we needed a secure development practice to manage risk and capacity, but because no one in the industry had done this before we had nothing to lean on. Our approach? Take inspiration from teams that had been through a similar scenario before.
In the early days of product development, engineers had very few restrictions on what or how they built. Eventually, the Product Development Lifecycle (PDLC) formalized a system that enabled governance and consistency.
“Great,” we thought, “let’s do that.” The response from our security team: Not so fast. Product development is different, they said. You don’t work within the same platforms or framework, they said.
No problem. We went away and broke down the component parts of PDLC then reconfigured them to work for a new use case. The result is the Agent & Automation Development Lifecycle (AADLC), a standardized process for documenting, evaluating, building, and releasing agents.
It’s a first-of-its-kind framework that can help any business looking to deploy AI agents at scale while ensuring governance and compliance.
What is the Agent & Automation Development Lifecycle?

AADLC defines a structured approach to internal AI development from request intake through requirements gathering, solution design, and validation all the way to launch. It’s designed to:
- Define clear ways-of-working, including RACI and hand-offs
- Ensure every initiative delivers business value while maintaining security, privacy, and compliance
- Help project owners keep track of what’s happening (and prove it to auditors)
One of the most important features of the framework is collaboration. It brings together AI Transformation, Data Analytics, Data Engineering, Business Systems, Privacy, and Security teams right from the outset, and documents exactly where handoffs need to take place.
Let’s go through it step-by-step.
How does AADLC work in practice?
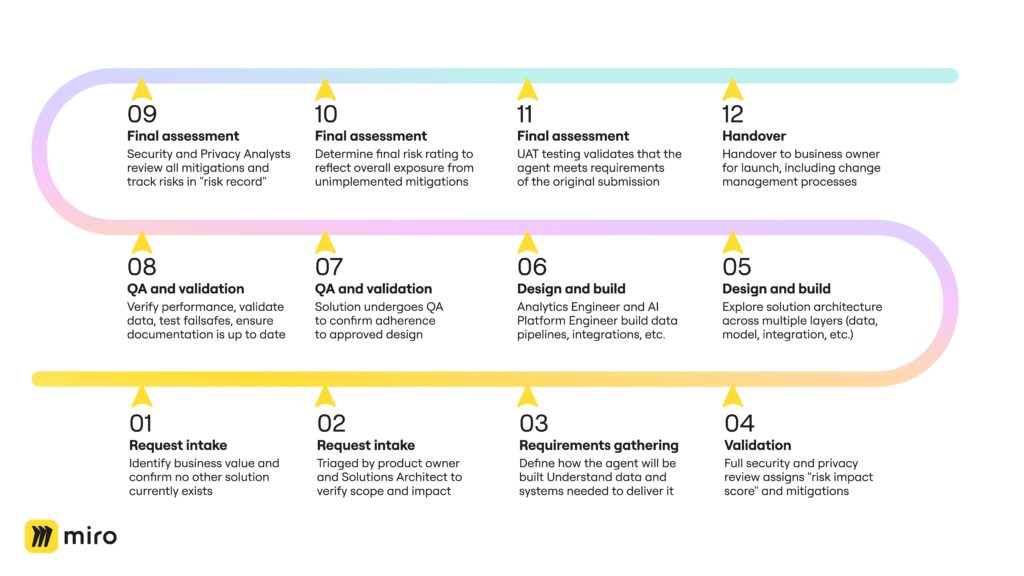
Stage 1: Request intake
According to McKinsey, 62% of organizations are experimenting with AI agents but fewer than half have advanced beyond a pilot. That suggests these agents aren’t compelling enough to roll out to the entire business.
AADLC solves that at the outset with two key questions:
- What business problem are we trying to solve?
- Do we already have an AI workflow or business technology solution for this problem?
The message to requestors: It’s not enough to want to build an agent. There has to be sufficient business value to make it worthwhile.
Every submission gets logged with enough detail for reviewers to understand scope and potential impact. It’s then reviewed by the product owner and Solutions Architect. If accepted, the project wins approval to begin in earnest.
Stage 2: Requirements gathering and validation
This is the first hand-off moment. The product owner, Solutions Architect, Corporate Security, Data Analytics, and Data Engineering come together to:
- Define how the agent will be built
- Understand the data and systems needed to deliver it
- Review and validate risks
The key output is a security and privacy assessment which assigns a “risk impact” score based on the type of data the agent will have access to. It also identifies risk mitigations that will be implemented in solution design.
Let’s say, for example, that the agent has access to sensitive data. Even if there’s a human in the loop reviewing the outputs, we need to be sure that the individual has clear steps to follow so they can do the job properly. In that case, the security and privacy team will dictate changes to how we’re building the end solution to make it as foolproof as possible.
Stage 3: Solution design and build
Now we’ve validated the business need and assessed the risk, we can start to figure out how we’re actually going to build the end solution.
This the job of the Enterprise Architecture and AI Transformation teams. A well-structured AI solution design separates concerns across distinct layers including a data layer (think metrics and access policies), an intelligence layer (LLM strategy), an orchestration layer (request routing, async messaging for scalability), an integration layer (API-first design, event-driven triggers), and finally an observability layer (distributed tracing, prompt/tool-call logging).
Once the solution design is approved, there’s another handshake moment where it’s passed to the build team and we move towards delivery. That team consists of:
- AI Platform Engineer: Builds flows, API integrations, and UI components
- Analytics Engineer: Builds data pipelines, data tables, vector stores, entity extraction logic, and integration user
Stage 4: QA and validation
Once development is complete, each solution undergoes structured QA and validation to confirm adherence to the approved design, criticality profile, and policy standards. This stage ensures, security, and compliance prior to handover into production or BAU. It includes:
- Verifying functional performance against design and success criteria
- Confirming all controls and mitigations defined in Stage 2 are implemented
- Validating data handling, logging, and error management
- Testing human review and fail-safe workflows
- Ensuring documentation and ownership details are up to date
Stage 5: Final assessment and handover
Following delivery of the solution, Security and Privacy Analysts review all identified mitigations. Where one or more mitigations cannot be fully implemented, a risk record is created to track and assess the residual exposure for the automation or agent.
If multiple mitigations remain outstanding, these are assessed collectively to determine the combined residual risk rating. This rating reflects the overall exposure arising from the unimplemented mitigations and establishes whether additional approvals, compensating controls, or design changes are required before release.
The business requestor is ultimately accountable for reviewing and formally accepting any residual risk. Once confirmed, the final decision and risk rating are recorded in the organization’s risk register, completing the assessment and ensuring full governance traceability.
Just as importantly, though, the solution also goes through user acceptance testing, where the business requestor circles all the way back to the original submission to validate that the agent meets requirements. If all boxes are ticked, the solution is ready for deployment.
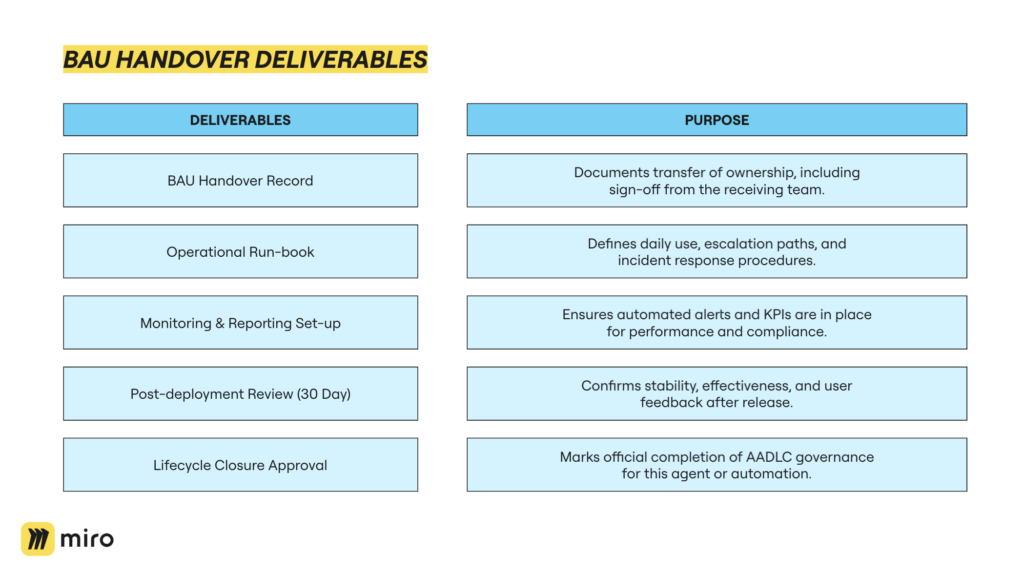
Depending on the scope of the agent or automation, deployment can be as simple as handing it over to an end user to go and launch, or it might go through a full change management process with a much larger team.
From chaos to confidence
We’ve been deploying AI agents using the AADLC framework for the last six months. They include a Product Taxonomy Categorizer created by the Scaled Customer Education team that lists every Miro capability and automatically updates in line with product changes.
Miro’s People team created the Personalized Automated, Communication Engine (or “Pace”) to deliver relevant internal communications to the right employee at the right time.
Another agent helps Sales Development Representatives create highly personalized outreach messages for Miro users within targeted accounts by aggregating data from multiple sources.
In all these instances (and many more) we’ve seen:
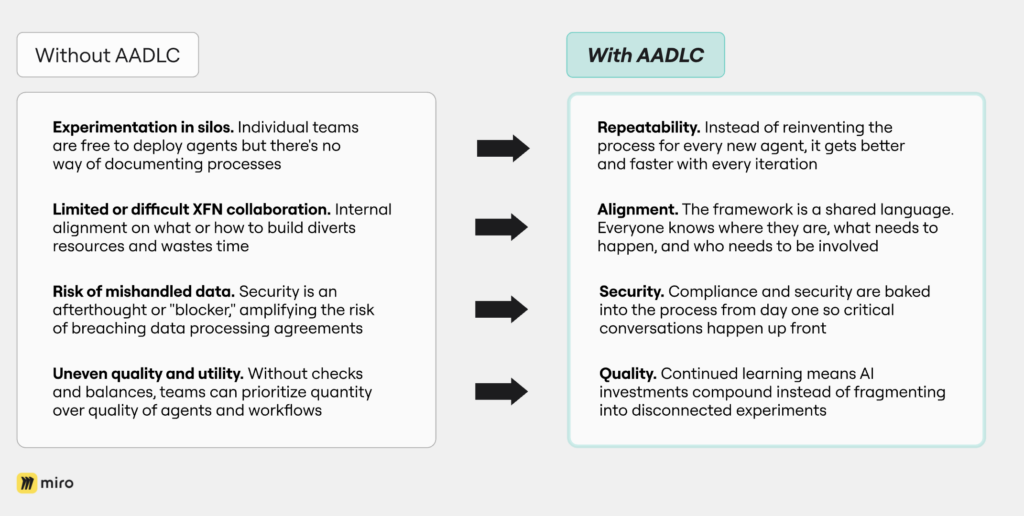
- Repeatability. We no longer reinvent the process for every new agent. That means we’re getting better and faster with every iteration.
- Alignment. The framework is our shared language. So instead of multiple alignment meetings, teams can just say, “We’re at Stage 2 security validation,” and everyone knows what that means, what needs to happen, and who needs to be involved.
- Security. Compliance and security are baked into the process from day one so those critical conversations happen up front instead of tripping teams up later on.
- Quality. We learn from every agent we deploy so our AI investments compound instead of fragmenting into disconnected experiments that don’t inform each other.
Getting started with AADLC
We’re sharing the AADLC framework because the industry needs standardization. Just like PDLC became the common language for product development, we believe AADLC can become the common language for AI agent deployment. So we’re here to help you implement it.
This blog post is just the first step. We’ll be publishing an AADLC template to the Miroverse very soon, and we’ll continue to share lessons learned from our implementation.
The challenge of managing disconnected AI experiments that duplicate effort, waste resources, and create AI silos isn’t going away. If anything, it’s accelerating as more organizations rush to deploy agents. But you don’t have to navigate it alone or invent your own framework from scratch.
AADLC exists because we needed it. We’re sharing it because you need it too. And we’re committed to helping you succeed with it.


