44 polubienia
146 użycia
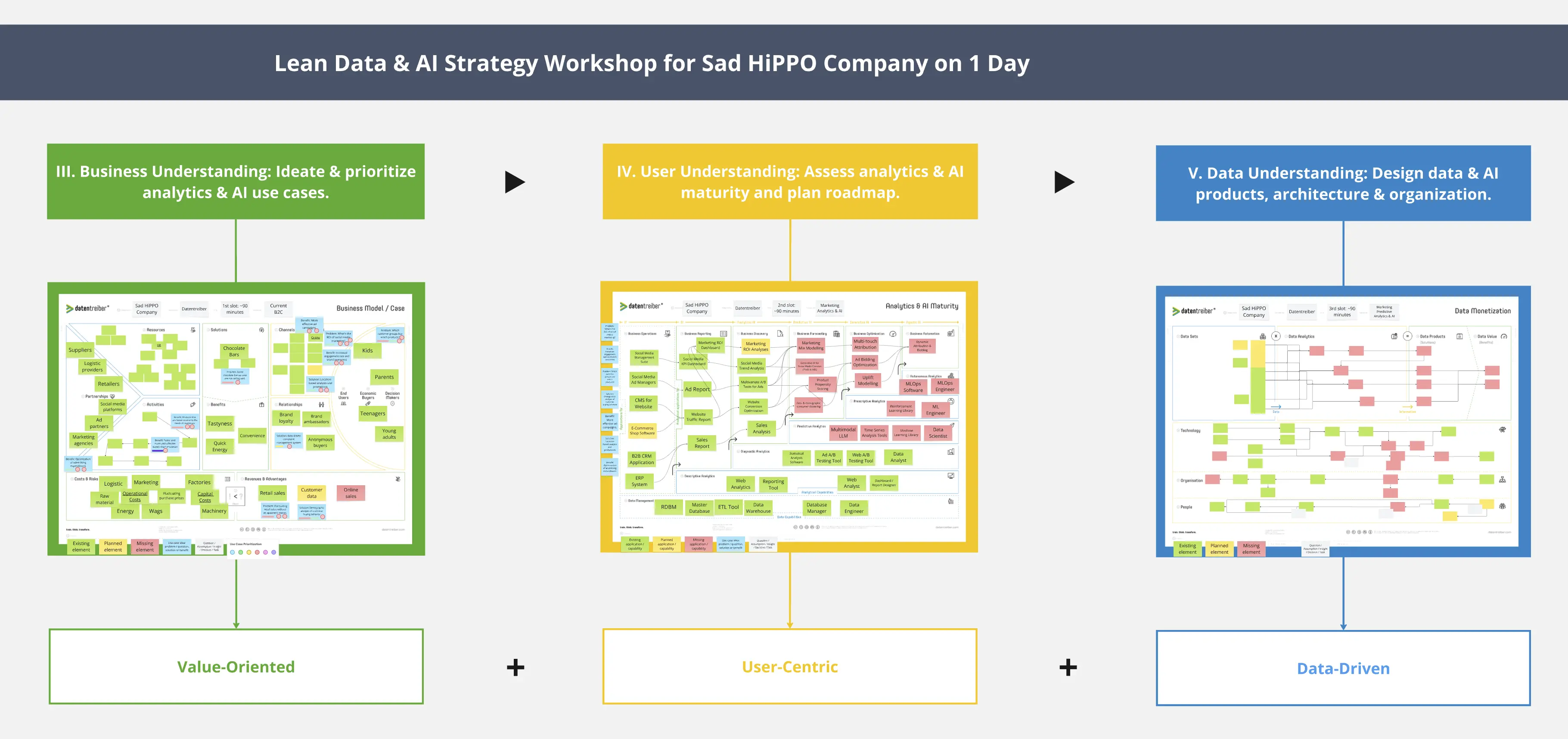
Przeanalizuj krajobraz danych, aby zidentyfikować kluczowe i użyteczne źródła danych dla produktu data/AI.
Po zidentyfikowaniu odpowiednich zbiorów danych dla produktu data/AI przy użyciu szablonu Data Monetization, kolejnymi krokami są zlokalizowanie, skategoryzowanie oraz sprawdzenie dostępności i jakości potencjalnych źródeł danych za pomocą Data Landscape.
1. Wypełnij nagłówek szablonu:
a) Oznacz Focus on w nagłówku szablonu białą karteczką z nazwą produktu danych/AI. Możesz skopiować karteczkę Focus on z Data Monetization canvasa, nad którym wcześniej pracowano.
b) Stopka: Dodaj legendę z karteczkami w odpowiadających kolorach:
Zielone karteczki: Zasób danych: źródło danych
Żółte karteczki: Zasób danych: źródło danych (z problemem)
Czerwone karteczki: Luka danych
Niebieskie karteczki: Produkt danych/AI lub pożądana informacja
Białe karteczki: Kluczowe założenie lub otwarte pytanie
② Aby ukierunkować eksplorację danych, dodaj niebieską karteczkę z nazwą produktu danych/AI lub — dla jeszcze większego skupienia — z pożądaną informacją w centralnym polu Produkt danych.
③-⑥ Rozważ wszystkie dane niezbędne lub przydatne dla tego produktu danych/AI albo dla pożądanej informacji. Użyj karteczek w następujących kolorach lub włącz wcześniej istniejące z pola Umieść w:
Zielony: Oznacza, że zestaw danych jest dostępny u źródła danych. Oznacz zieloną karteczkę samoprzylepną w następujący sposób: " zestaw danych: źródło danych". Jeśli zestaw danych jest dostępny w różnych wersjach, formatach, źródłach itp., dodaj kilka zielonych karteczek samoprzylepnych i dopisz uwagi do oznaczenia, np. "zestaw danych: źródło danych (uwaga)"
Czerwony: Oznacza, że zestaw danych nie jest dostępny. Nadaj czerwonej karteczce samoprzylepnej opisowy tytuł.
Żółty: Oznacza, że zestaw danych jest dostępny, ale ma problemy z dostępnością, jakością, prywatnością, bezpieczeństwem itp. Oznacz żółtą karteczkę samoprzylepną w następujący sposób: "zestaw danych: źródło danych (problem)".
Umieść te karteczki samoprzylepne w jednym z czterech kwadrantów krajobrazu danych, a następnie omów konsekwencje:
③ Dane własne: Wykorzystywanie zestawów danych własnych może zapewnić trwałą przewagę konkurencyjną, ponieważ konkurenci mogą nie być w stanie ich powtórzyć. Zestawy danych własnych nie mają ograniczeń w użytkowaniu, dlatego priorytetowo opieraj swoje produkty danych i AI na danych własnych.
④ Dane zdobyte: Dane zdobyte, na przykład od klientów lub dostawców, mogą podlegać ograniczeniom użytkowania wynikającym z indywidualnych umów lub przepisów prawa (np. przepisów o ochronie danych osobowych). Jeśli istnieje potencjalny problem prawny, zmień karteczkę samoprzylepną z zielonej na żółtą, aby wskazać to ryzyko i opisz problem.
⑤ Dane płatne: Dane płatne często wiążą się z bardziej restrykcyjnymi ograniczeniami, a wyłączność zwykle nie jest gwarantowana. Często różne działy tej samej firmy nieświadomie kupują ten sam zestaw danych wielokrotnie. Aby uniknąć powielania, zawsze dokładnie sprawdź dane i istniejące umowy licencyjne przed finalizacją zakupu.
⑥ Dane publiczne: Dane publiczne zazwyczaj nie są wyłączne, a wiele zbiorów danych ma restrykcyjne prawa użytkowania, np. tylko do użytku niekomercyjnego. Warto też zauważyć, że otwarte dane mogą podlegać umowom typu "copyleft" — użycie takich danych może wymagać udostępnienia Twoich produktów danych jako open source.
Zdecyduj także, czy to dane surowe, czy pochodne, i przemyśl konsekwencje:
a) Dane surowe: Zawierają wszystkie oryginalne informacje, ale mogą być trudne w obsłudze i efektywnym wykorzystaniu.
b) Dane pochodne: Te dane przeszły procesy takie jak oczyszczanie, normalizacja, agregacja, anonimizacja itp., co skutkuje utratą części pierwotnych informacji. Zastanów się, jakie konsekwencje mają te zmiany dla użyteczności danych.
W zależności od wymogów prawnych i dotyczących przetwarzania ustal najbardziej odpowiednie źródła danych dla swojego produktu data/AI. Umieść obok wybranych zestawów danych białe karteczki samoprzylepne, aby udokumentować swoje decyzje i ich uzasadnienia, i/lub usuń niepotrzebne karteczki.
W uczeniu maszynowym większa ilość danych często poprawia wydajność modelu. Jednak firmy zazwyczaj skupiają się wyłącznie na swoich danych, pomijając ogromny potencjał danych publicznych i płatnych. Aby poszerzyć zasoby danych, rozważ zbadanie dodatkowych możliwości pozyskania danych:
③ Dane własne: Jak możemy zmodyfikować nasz model biznesowy i/lub procesy, aby zbierać więcej lub inne rodzaje danych? Przejrzyj kanwy Business Model, Value Chain, Customer Touchpoints oraz Analytics & AI Maturity (pole Business Operations) w poszukiwaniu wskazówek.
④ Earned Data: Jakie dodatkowe dane mogliby nam dostarczyć nasi klienci i partnerzy? Sprawdź kanwę Business Model, aby zidentyfikować potencjalnych klientów i partnerów i użyj (kopii) kanwy Business Model, aby przeanalizować model biznesowy swoich klientów lub partnerów (B2B).
⑤ Paid Data: Jakie zewnętrzne dane moglibyśmy kupić lub wymienić na nasze dane? Użyj kanwy Value Chain, aby przeanalizować cały łańcuch wartości w Twojej branży i poszukaj klientów Twoich klientów i/lub dostawców Twoich dostawców.
⑥ Public Data: Jakie publiczne źródła danych mogą zawierać istotne informacje? Myśl nieszablonowo i bądź kreatywny: czy istnieją jakieś zmienne zastępcze (proxy)? Na przykład liczba edycji na stronie Wikipedia o filmie może silnie przewidywać przychody z tego filmu.
Ostatnim, ale kluczowym krokiem jest upewnienie się, że wszystkie zestawy danych są połączone. Na przykład zidentyfikuj wszystkie niezbędne identyfikatory lub inne dane łączące (np. datę, współrzędne GPS, kod pocztowy itp.), zlokalizuj źródło danych (np. główny system bazy danych), oceń dostępność źródła (zielona, żółta lub czerwona karteczka) i umieść karteczki w odpowiadających polach Link Data (③-⑥c), w zależności od pochodzenia źródeł danych.
Połącz każdą karteczkę wskazującą źródło danych z odpowiadającą karteczką danych łączących za pomocą linii przerywanych, bazując na wspólnych identyfikatorach lub danych łączących. Na końcu cały graf powinien być w pełni połączony, aby umożliwić kompleksową integrację i analizę danych.
Datentreiber oferuje Ci nie tylko ten szablon Miroverse, ale także:
Data & AI Business Design Kit oferuje liczne, otwarte szablony typu canvas do stosowania metody Data & AI Business Design.
Ponadto dostępna jest bezpłatna Data & AI Business Design Community, służąca wymianie doświadczeń, udziałowi w wydarzeniach i korzystaniu z treści eksperckich.
Płatne kursy online i stacjonarne z certyfikacją dostępne są w Data & AI Business Design Academy.
Wiele dodatkowych narzędzi do zarządzania, szablonów warsztatów i wzorców projektowych znajdziesz w naszym komercyjnym Data & AI Business Design Bench.
Nasze Data & AI Business Consulting oferuje wsparcie dla Twojej strategii danych i AI oraz w projektach związanych z innowacjami i transformacją.
Jeśli jesteś zainteresowany(-a) lub masz pytania bądź uwagi, skontaktuj się z nami pod adresem: info@datentreiber.de.
Prawa autorskie: Wszelkie prawa zastrzeżone przez Datentreiber GmbH.

Martin Szugat
Data & AI Business Catalyst @ Datentreiber
To help companies to transform into data-driven, AI-powered businesses and innovate data & AI products, I've invented the Data & AI Business Design Method and our company Datentreiber open sourced the Data & AI Business Design Kit. I'm a Miro MVP and a Miro Solution Partner.