66 likes
878 utilisations
Un modèle de journal d'incidents de garde transforme la manière dont les équipes d'ingénierie capturent, suivent et analysent les incidents système depuis l'alerte initiale jusqu'à la résolution finale. Construit avec la puissante fonctionnalité Tables de Miro, ce modèle crée un centre structuré où chaque détail d'incident est accessible au même endroit – des niveaux de gravité et temps de réponse à l'analyse des causes fondamentales et aux actions de suivi.
Considérez-le comme votre centre de commande d'incidents qui ne disparaît pas quand la crise est résolue. Au lieu de perdre des insights précieux dans la précipitation pour rétablir le service, vous construisez une base de données complète qui révèle des schémas, suit les performances de l'équipe et guide vos améliorations en matière de fiabilité.
Miro prend en charge à la fois la collaboration en temps réel lors des incidents actifs et l'analyse asynchrone après coup, de sorte que vos équipes distribuées peuvent se coordonner efficacement, que ce soit pour gérer des crises à 3 heures du matin ou pour mener des analyses approfondies la semaine suivante.
Transformez votre processus de réponse aux incidents avec ces six étapes qui transforment une réaction de gestion de crise en une amélioration proactive du système.
Commencez par personnaliser les colonnes du modèle pour qu'elles correspondent au workflow de votre équipe. Configurez les champs pour l'ID d'incident, les horodatages, les services affectés, les niveaux de gravité et les ingénieurs assignés. Les tables de Miro sont flexibles : ajoutez des champs personnalisés pour votre infrastructure spécifique, vos procédures d'escalade ou vos exigences de conformité.
Votre modèle devient un document vivant qui s'adapte à la complexité de votre système, plutôt qu'un cadre rigide qui vous impose le processus de quelqu'un d'autre.
Lorsque des alertes se déclenchent, votre ingénieur d'astreinte peut enregistrer immédiatement l'incident directement dans Miro. Capturez les symptômes initiaux, les utilisateurs affectés et l'évaluation préliminaire de l'impact tant que les détails sont frais. La collaboration en temps réel de Miro permet à votre équipe de réponse de voir les mises à jour instantanément, qu'elle se connecte depuis son ordinateur portable ou son appareil mobile.
Utilisez Miro IA pour aider à structurer les descriptions d'incidents et suggérer des étiquettes pertinentes basées sur des incidents similaires précédents. Cela accélère le processus de consignation lorsque chaque minute compte.
Au-delà de la simple consignation de données, créez des plannings visuels et des cartes de dépendances directement à côté de vos dossiers d'incidents. Lorsque plusieurs services sont affectés, utilisez le canevas visuel de Miro pour cartographier la cascade des pannes et coordonner les efforts de récupération parallèles.
Votre journal des incidents devient plus qu'une simple feuille de calcul – il devient un centre de commandement où les détails techniques rencontrent une clarté visuelle.
Après que la crise immédiate soit passée, votre modèle soutient des revues post-incidents approfondies. Utilisez les relations parent-enfant dans les tables pour lier les incidents à leurs causes sous-jacentes, et créez des diagrammes visuels qui retracent la chaîne de défaillances du déclenchement à la résolution.
Les équipes peuvent collaborer de manière asynchrone sur la reconstruction du planning, ajoutant leurs perspectives et insights sans cycles interminables de réunions.
Les capacités de filtrage et de tri de Miro transforment votre collection d'incidents en insights exploitables. Identifiez rapidement vos modes de défaillance les plus fréquents, suivez les tendances du temps moyen de résolution et repérez les schémas préoccupants à travers les services ou les périodes de temps.
Les champs de formule calculent automatiquement des indicateurs clés tels que les pourcentages de disponibilité et les taux d'escalade, vous fournissant les données nécessaires pour la planification des capacités et les discussions sur la fiabilité.
Reliez vos enseignements d'incidents à des actions concrètes en utilisant les vues Kanban dans le même espace de travail. Convertissez les résultats sur les causes racines en tâches d'ingénierie prioritaires, et suivez les progrès des remédiations parallèlement à votre historique d'incidents.
Votre journal d'incidents devient la base des roadmaps de fiabilité, et pas seulement un enregistrement des problèmes passés.
Les besoins de réponse aux incidents de chaque équipe d'ingénierie sont uniques, mais ces éléments fondamentaux créent une base complète pour l'apprentissage et l'amélioration.
Capturez les éléments essentiels du qui, quoi, quand qui encadrent chaque incident. Incluez les identifiants uniques, les horodatages de découverte, les temps de résolution et la chronologie complète des actions de réponse. Ce planning devient crucial pour l'analyse post-incident et l'identification des goulets d'étranglement dans votre processus de réponse.
Documentez le rayon d'impact de chaque incident : services affectés, impact sur les utilisateurs, implications sur le chiffre d'affaires et dépendances externes. Des classifications claires de la gravité aident à prendre des décisions d'escalade et à allouer les ressources pendant les incidents en cours.
Suivez qui a répondu, quand ils ont rejoint, et quelles actions ils ont prises. Ces informations aident à organiser les plannings d'astreinte, identifient les lacunes en matière de connaissances, et assurent que le mérite revient aux ingénieurs qui ont maintenu vos systèmes en fonctionnement.
La partie la plus précieuse de tout journal d'incident est l'apprentissage. Capturez non seulement ce qui s'est cassé, mais pourquoi cela s'est cassé, ce qui l'a réparé, et ce qui pourrait prévenir des pannes similaires. Ces insights orientent vos investissements en fiabilité et vos décisions architecturales.
Transformez les insights post-incident en actions traçables. Liez les tâches de remédiation à leurs incidents d'origine afin de pouvoir mesurer l'efficacité de vos améliorations en matière de fiabilité au fil du temps.

Miro
Espace de travail pour l’innovation enrichi par l’IA
Miro réunit vos équipes et l’IA pour qu’elles puissent planifier, cocréer et construire plus vite la prochaine grande innovation. Avec Miro, plus de 100 millions de responsables de produit, designers, ingénieurs et autres professionnels passent de la phase de découverte à la livraison finale sur un canevas partagé et centré sur l’IA. En intégrant l’IA au cœur du travail d’équipe, Miro brise les silos, renforce l’alignement et accélère l’innovation. Le canevas sert de prompt et les workflows d’IA collaboratifs de Miro permettent aux équipes de maintenir le rythme, de généraliser les nouvelles méthodes de travail et de mener à bien la transformation à l’échelle de l’entreprise.
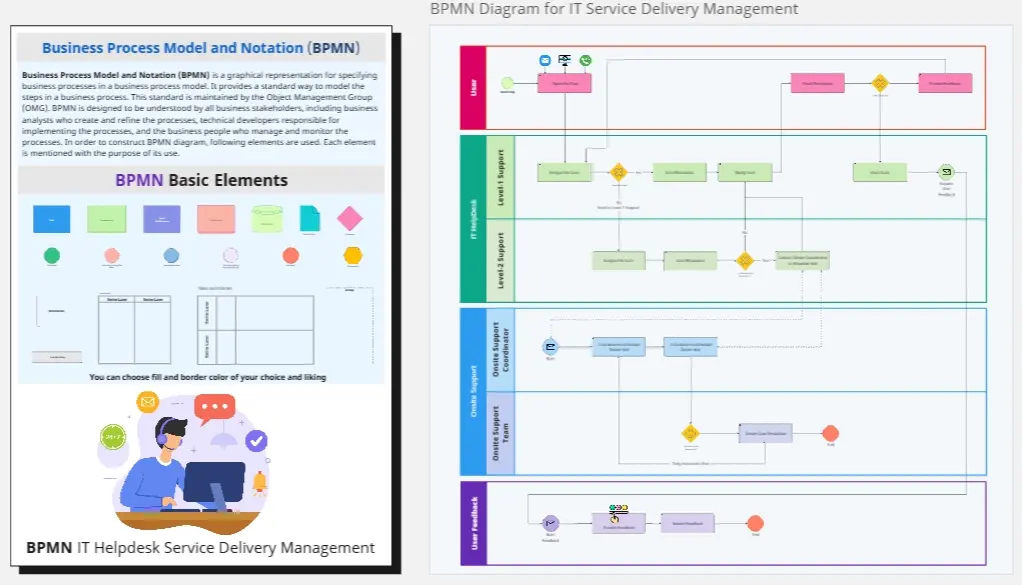
BPMN pour la gestion de la prestation de services informatiques
Le modèle de Diagramme BPMN pour les processus IT cartographie et optimise les workflows IT, de la gestion des incidents à la prestation de services. Idéal pour les équipes IT cherchant à améliorer la gestion des services, rationaliser les opérations et renforcer la qualité du service, ce modèle offre un cadre visuel pour identifier les goulots d'étranglement, améliorer la communication et atteindre une gestion efficace des processus IT.

Canevas d'analyse rétrospective sans blâme
Le canevas de post-mortem sans blâme est un cadre structuré pour mener des post-mortems sans blâme après des incidents ou des échecs. Il propose des sections pour documenter le planning, l'impact, les causes profondes et les informations exploitables. Ce modèle favorise une culture d'apprentissage et d'amélioration sans blâme, permettant aux équipes d'analyser les incidents de manière objective, d'identifier les problèmes systémiques et de mettre en œuvre des mesures préventives. En favorisant la transparence et la responsabilité, le Canevas de Postmortem Sans Blâme permet aux organisations d'apprendre de leurs échecs et de renforcer leur résilience, favorisant ainsi l'amélioration continue et la fiabilité.

Modèle d’analyse des causes (RCA)
Le modèle d’analyse des causes (RCA) est un outil structuré qui aide les équipes à découvrir les raisons sous-jacentes derrière des problèmes ou événements spécifiques. En identifiant et en traitant ces causes profondes, plutôt que de simplement traiter les symptômes, les organisations peuvent favoriser des solutions à long terme et prévenir les défis récurrents, menant à des opérations plus efficaces et durables.
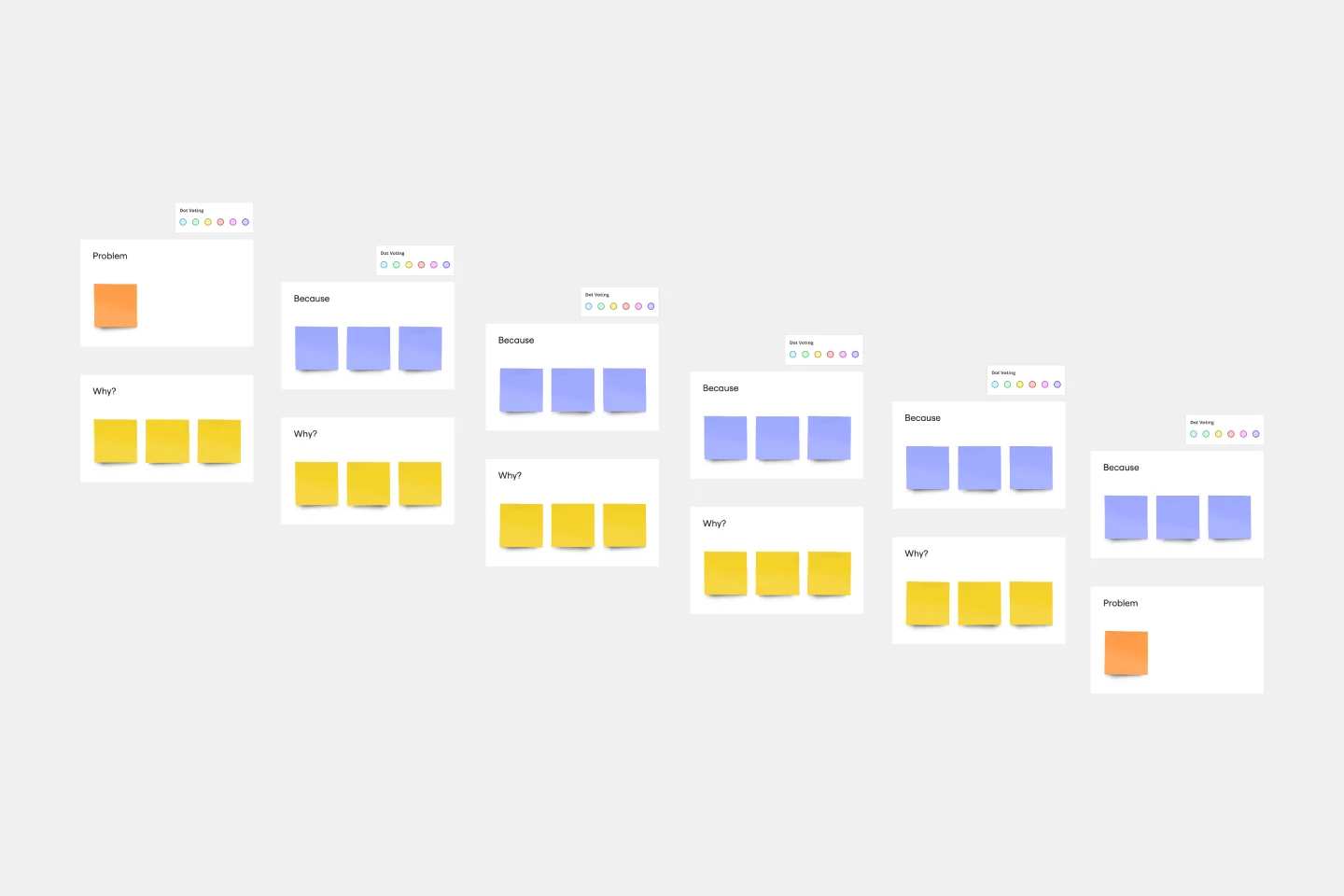
Modèle 5 Whys
Prêt à découvrir la cause profonde du problème ? Il n’y a pas de méthode plus simple que la technique des 5 Pourquoi. Vous commencerez par une question simple : Pourquoi le problème est-il survenu ? Ensuite, vous continuerez à poser la question, jusqu’à quatre fois encore, jusqu’à ce que la réponse devienne claire et que vous puissiez travailler à une solution. Et les fonctionnalités de Miro améliorent l’approche : vous pouvez poser des questions aux membres de l’équipe dans le chat ou les @mentionner dans les commentaires, et utiliser des pense-bêtes codés par couleur pour mettre en évidence les problèmes qui sont au cœur du problème à résoudre.
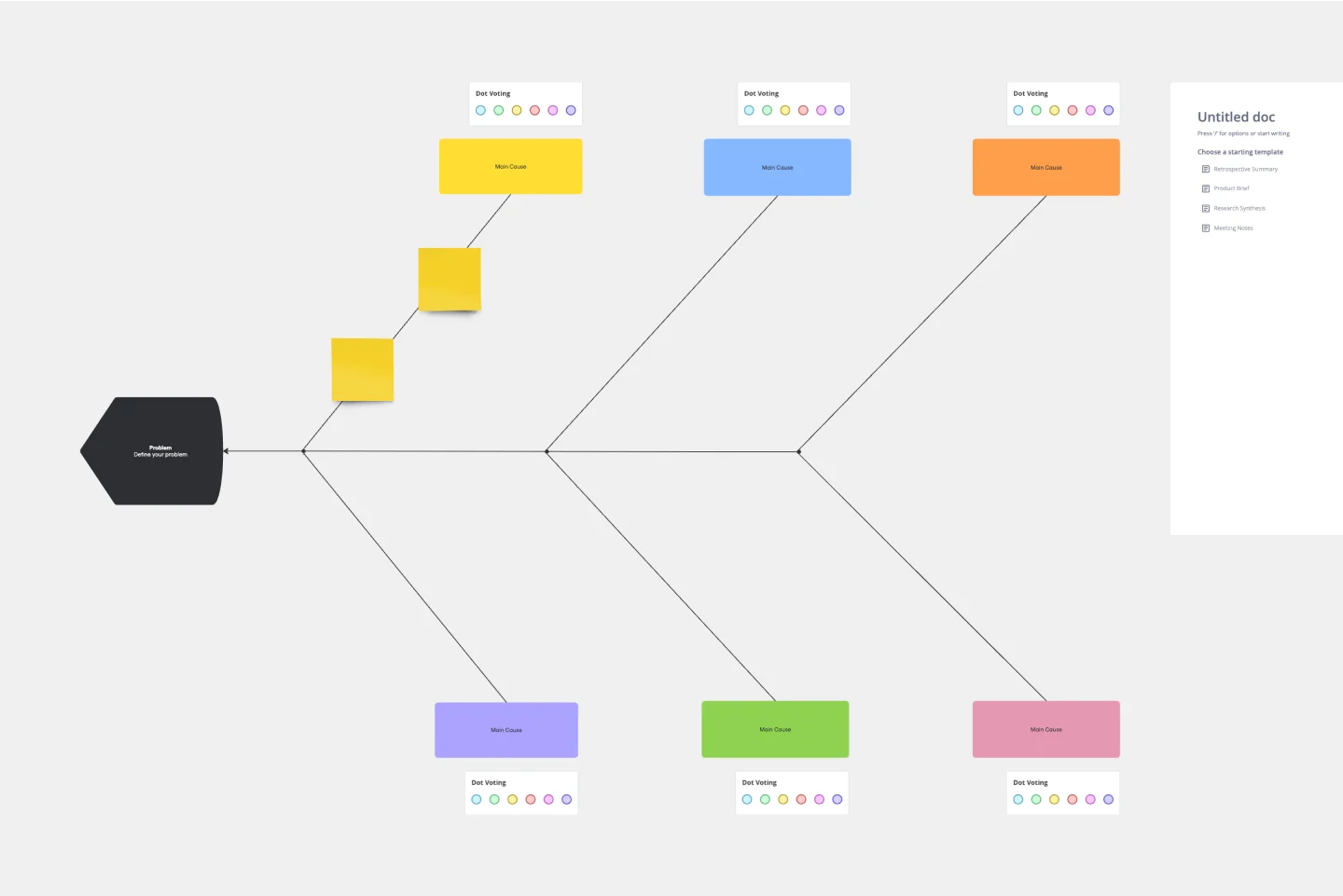
Modèle de diagramme d’Ishikawa
Quelle est la meilleure façon de résoudre un problème rencontré par votre équipe ? Allez directement à la racine. Cela signifie identifier les causes profondes du problème, et les diagrammes d’Ishikawa sont conçus pour vous aider à le faire au mieux. Également connus sous le nom de diagrammes de causes à effet (d’après l’expert japonais en contrôle de qualité Kaoru Ishikawa), ces diagrammes permettent aux équipes de visualiser toutes les causes possibles d’un problème, d’explorer et de comprendre comment elles s’emboîtent de manière holistique. Les équipes peuvent également utiliser les diagrammes d’Ishikawa comme point de départ pour réfléchir à ce qui pourrait être la cause profonde d’un problème futur.
BPMN pour la gestion de la prestation de services informatiques
Le modèle de Diagramme BPMN pour les processus IT cartographie et optimise les workflows IT, de la gestion des incidents à la prestation de services. Idéal pour les équipes IT cherchant à améliorer la gestion des services, rationaliser les opérations et renforcer la qualité du service, ce modèle offre un cadre visuel pour identifier les goulots d'étranglement, améliorer la communication et atteindre une gestion efficace des processus IT.
Canevas d'analyse rétrospective sans blâme
Le canevas de post-mortem sans blâme est un cadre structuré pour mener des post-mortems sans blâme après des incidents ou des échecs. Il propose des sections pour documenter le planning, l'impact, les causes profondes et les informations exploitables. Ce modèle favorise une culture d'apprentissage et d'amélioration sans blâme, permettant aux équipes d'analyser les incidents de manière objective, d'identifier les problèmes systémiques et de mettre en œuvre des mesures préventives. En favorisant la transparence et la responsabilité, le Canevas de Postmortem Sans Blâme permet aux organisations d'apprendre de leurs échecs et de renforcer leur résilience, favorisant ainsi l'amélioration continue et la fiabilité.
Modèle d’analyse des causes (RCA)
Le modèle d’analyse des causes (RCA) est un outil structuré qui aide les équipes à découvrir les raisons sous-jacentes derrière des problèmes ou événements spécifiques. En identifiant et en traitant ces causes profondes, plutôt que de simplement traiter les symptômes, les organisations peuvent favoriser des solutions à long terme et prévenir les défis récurrents, menant à des opérations plus efficaces et durables.
Modèle 5 Whys
Prêt à découvrir la cause profonde du problème ? Il n’y a pas de méthode plus simple que la technique des 5 Pourquoi. Vous commencerez par une question simple : Pourquoi le problème est-il survenu ? Ensuite, vous continuerez à poser la question, jusqu’à quatre fois encore, jusqu’à ce que la réponse devienne claire et que vous puissiez travailler à une solution. Et les fonctionnalités de Miro améliorent l’approche : vous pouvez poser des questions aux membres de l’équipe dans le chat ou les @mentionner dans les commentaires, et utiliser des pense-bêtes codés par couleur pour mettre en évidence les problèmes qui sont au cœur du problème à résoudre.
Modèle de diagramme d’Ishikawa
Quelle est la meilleure façon de résoudre un problème rencontré par votre équipe ? Allez directement à la racine. Cela signifie identifier les causes profondes du problème, et les diagrammes d’Ishikawa sont conçus pour vous aider à le faire au mieux. Également connus sous le nom de diagrammes de causes à effet (d’après l’expert japonais en contrôle de qualité Kaoru Ishikawa), ces diagrammes permettent aux équipes de visualiser toutes les causes possibles d’un problème, d’explorer et de comprendre comment elles s’emboîtent de manière holistique. Les équipes peuvent également utiliser les diagrammes d’Ishikawa comme point de départ pour réfléchir à ce qui pourrait être la cause profonde d’un problème futur.